
Jest takie słynne powiedzenie – przygotowanie jest podstawą każdego sukcesu. Nie inaczej ma się sytuacja w kontekście incydentów.
Aby wiedzieć, co i jak monitorować, chronić i zabezpieczać, na samym początku należy mieć określony katalog zasobów IT (IT Assets list). Jeśli katalog zasobów IT został stworzony, to w tym miejscu należałoby podjąć rozważanie dotyczące tego, jakie zasoby należy zabezpieczać oraz monitorować przy zmieniającym się profilu ryzyka. Innymi słowy, pada pytanie – nad którymi zasobami IT należałoby się bardziej pochylić. Zapewne u większości czytelników narzuca się odpowiedź – nad wszystkimi! Przecież w jednym z poprzednich artykułów zostało jasno powiedziane: „system jest tak silny jak jego najsłabsze ogniwo”. Rzeczywiście, taka logika jest poprawna, natomiast w życiu realnym niestety mamy pewne ograniczenia: czasowe, przerobowe, finansowe, etc.
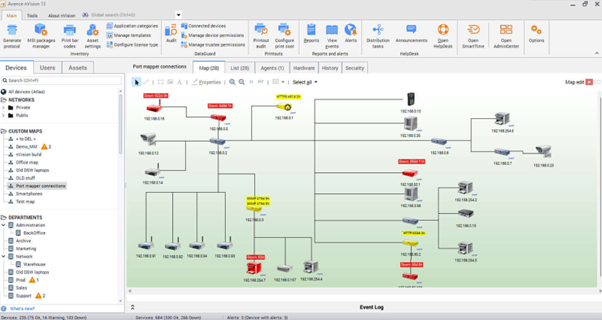
Przykład katalogu zasobów IT – Axence nVision
A zatem, jak należałoby do sprawy podejść? Aby na to pytanie odpowiedzieć, musimy wprowadzić pojęcie krytyczności zasobu. Co to jest ów krytyczność zasobu? To nic innego jak zdefiniowanie, jaki będzie skutek, gdy atakujący z sukcesem skompromituje ten zasób.
Przykład:
W naszej infrastrukturze sieciowej mamy kilka serwerów. Część z nich to serwery utrzymujące aplikacje wewnętrzne, a część z nich to serwery, które hostują usługi dla klientów. W tej drugiej grupie znajduje się np. serwer X, który świadczy usługę dla dużego klienta korporacyjnego, gdzie zysk z niego to 20 tys. PLN miesięcznie. Jeżeli haker zaatakuje tę usługę z sukcesem, wówczas nie będzie ona dostarczana do klienta oraz wiarygodność naszej firmy znacząco spadnie. Pomijając kary umowne za niedostarczenie usługi, będziemy „w plecy” 20 tys. PLN w skali miesiąca, czyli w skali roku 240 tys. PLN. Czy nasza firma będzie w stanie sobie pozwolić na taką utratę zysku?
Mając listę zasobów IT i przypisaną ich krytyczność na bazie potencjalnej straty wynikającej z udanego ataku, należy przeorganizować tę listę tak, aby na samej górze znajdowały się zasoby najbardziej krytyczne, a na dole najmniej krytyczne. Gdy taka lista powstanie, wówczas będziemy mogli, patrząc na nasze capacity, zająć się tymi najistotniejszymi z punktu widzenia naszej organizacji.
UWAGA: Stworzony oraz odpowiednio utrzymywany katalog zasobów to absolutny fundament działania każdej organizacji. Bez pełnej wiedzy na temat tego, co mamy w swojej infrastrukturze, absolutnie niewykonalne jest zabezpieczenie owej infrastruktury, nie wspominając o obsłudze incydentów. No bo jak obsłużyć incydent serwera, o którym nie wiemy, że w ogóle istnieje?
Implementacja Procesu Obsługi Incydentów:
Zakładając, że katalog zasobów IT oraz ich krytyczność zostały zdefiniowane, teraz należy zająć się implementacją procesu obsługi incydentów (oczywiście przy wcześniejszym stworzeniu tego procesu). Proces ten powinien być stworzony przez kierownika działu bezpieczeństwa IT lub przez kierownika zespołu incident response. Zatwierdzony zaś przez najwyższe kierownictwo. Dlaczego? Ponieważ niektóre działania obsługi incydentów mogą powodować straty (oczywiście mniejsze niż atak hakerski).
Przykład:
Przed chwilą dostaliśmy zgłoszenie, że aplikacja hostowana przez jeden z naszych serwerów została zaatakowana. Zaglądamy w konsolę do monitorowania tej aplikacji, gdzie ukazuje się nam następujący widok:
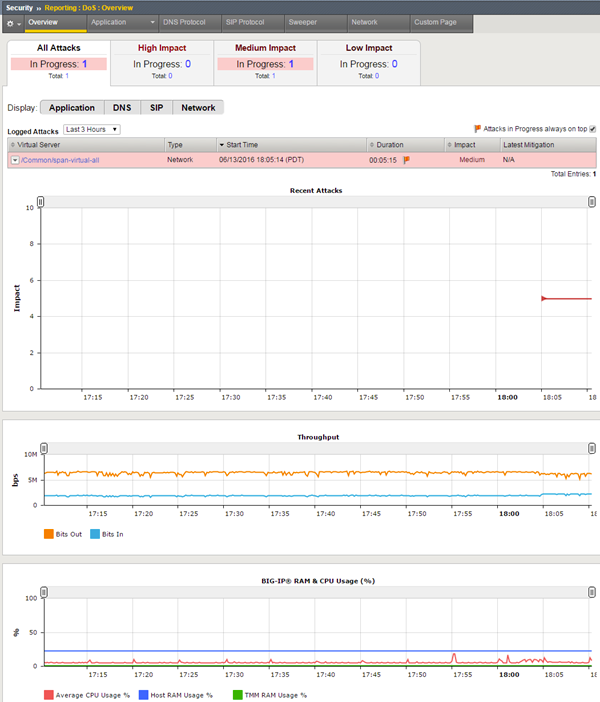
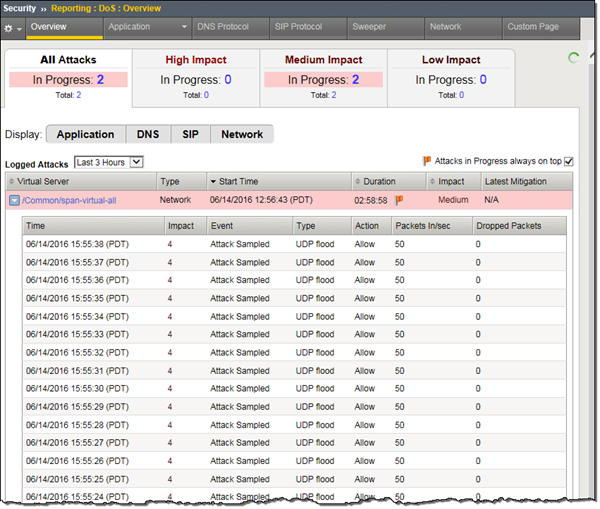
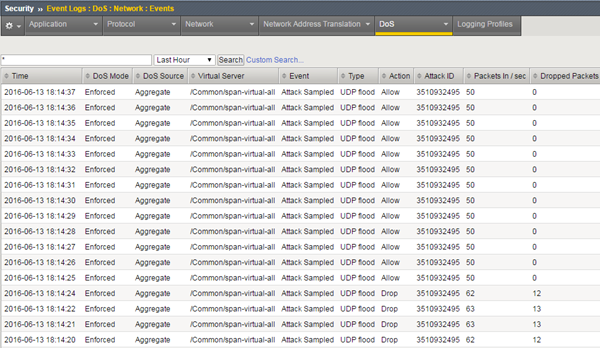
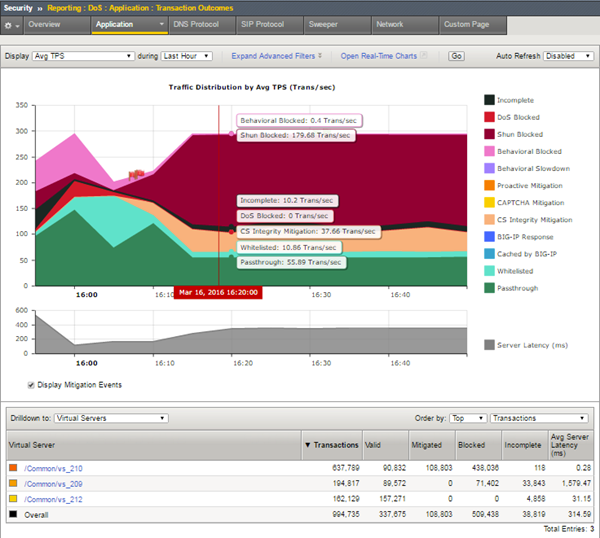
Widzimy ewidentnie, że jesteśmy ofiarami ataku typu DDoS (Distributed Denial of Service), który uderza w dostępność naszej aplikacji i serwera. Jako że aplikacja (gdy atak trwa) nie jest dostępna i nie może świadczyć usług, a więc ponosimy straty, musimy podjąć decyzję, co należy zrobić. Czy wyseparować ten serwer z infrastruktury, czy może zostawić go i wdrożyć jakąś regułę na firewallu? To oczywiście zależy od możliwości, które mamy (nad możliwościami zabezpieczeń będziemy pochylać się w kolejnych artykułach) i od krytyczności, jaką przypisaliśmy do tego serwera. Natomiast ścieżka akceptacji proponowanych działań musi być jasno i klarownie zdefiniowana w procesie obsługi incydentów, tak, aby uniknąć podejścia na zasadzie „wszystkie ręce na pokład”.
Testowanie:
Każdy dokument, każdy proces, jeśli nie jest zaimplementowany, testowany i wykonywany, jest zwyczajnie martwy. Każda organizacja się zmienia, ewoluuje i aby nadal być przygotowanym na potencjalne incydenty, musimy na bieżąco, w określonych interwałach czasowych, sprawdzać, czy aby na pewno proces działa i przystaje do współczesnych realiów naszej organizacji.



Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.