
Jednym z bardziej znanych sloganów w branży ITsec jest z pewnością zdanie: „nie istnieje system w pełni bezpieczny”. Co to właściwie oznacza? Intuicyjnie, chyba każdy z czytelników wie, o co chodzi, natomiast technicznie możemy powiedzieć, że każdy system będzie miał ryzyko niezerowe. To z kolei implikuje fakt, iż incydenty się wydarzały, wydarzają i wydarzać będą. Zatem każda dojrzała organizacja powinna mieć jasno określony proces obsługi incydentów. Dlaczego? Posłużmy się przykładem. Wyobraźmy sobie, że padliśmy ofiarą włamania. W momencie detekcji tego przykrego zdarzenia wpadamy w panikę i zaczynamy przestawiać różne przedmioty, aby określić, co nam zginęło.
Jaki jest tego efekt? Swoim działaniem, możemy nieintencjonalnie zatrzeć ślady zostawione przez prawdziwego sprawcę (czyli de facto, możemy zniszczyć wartość dowodową śladów) co spowoduje, że określenie metody włamania oraz aktywności włamywacza mogą okazać się niemożliwe do określenia. Dokładnie tak samo ma się sytuacja w kontekście technologicznym. Proces obsługi incydentów musi mieć zdefiniowane aktywności wraz z przypisanymi odpowiedzialnościami oraz kolejnością ich wykonywania.
Opis procesu
Pozwolę sobie użyć przykładu, aby przedstawić jak działa wzorcowy proces obsługi incydentów. Wyobraźmy sobie sytuację, aczkolwiek niestety dosyć częstą, że przychodzi zgłoszenie. Właśnie, niestety niewiele wiadomo, ale jednak zadziałał jakiś mechanizm monitoringu, alertowania i administrator również ma wątpliwości co do charakteru wspomnianej przez niego aktywności hosta A.B.C.D, a zatem jest podejrzenie incydentu.
Faza przygotowania
Proces obsługi incydentów, jak to zostało wspomniane powyżej, musi być jasno określony ale również przetestowany, aby sprawdzić, czy rzeczywiście spełnia swoją funkcje i jest efektywny.
Faza detekcji i analizy
Aby w ogóle mieć świadomość, że jest jakieś zdarzenie, które może być incydentem, organizacja potrzebuje mieć narzędzia, które monitorują aktywność użytkowników na (przynajmniej) krytycznych systemach. Bez tego, organizacja będzie absolutnie niewidoma na zagrożenia. Na bazie zebranych logów, pochodzących z systemów monitorowania i reagowania (SIEM) można dopiero podjąć się analizy, czy analizowane zdarzenie jest rzeczywiście incydentem, czy też nie.
Zobaczmy więc na logi, które załączył nam do wiadomości administrator będący autorem powyższej wiadomości.
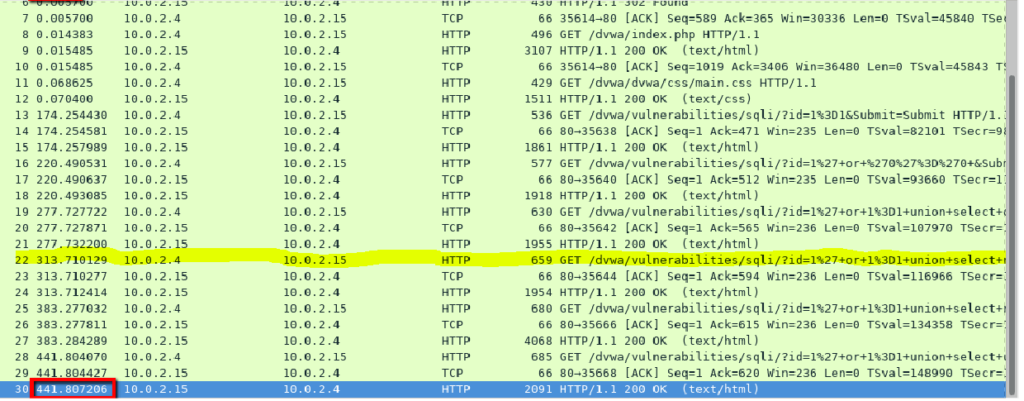
No i teraz wszystko staje się bardziej jasne. Widać jak na dłoni, że użytkownik o adresie IP 10.0.2.4 próbuje w parametrze ID naszej aplikacji, wstrzykiwać fragmenty zapytań SQLowych. Zwróćmy uwagę na pakiet np. o numerze 22. Jest tam ewidentna próba wywołania zapytania UNION SELECT w parametrze ID aplikacji webowej. Z pewnością nie jest to typowe działanie użytkownika względem parametru ID. Mamy bardzo duże podejrzenie, że jest atak SQL Injection (przeczytaj więcej w artykule: SQL Injection, czyli aplikacje webowe w niebezpieczeństwie)
Aby teraz określić kolejne kroki, to musimy zweryfikować, czy atak był udany i jakie są jego potencjalne skutki.
Przeglądając odpowiedzi aplikacji do atakującego, możemy natrafić np. na taki pakiet:
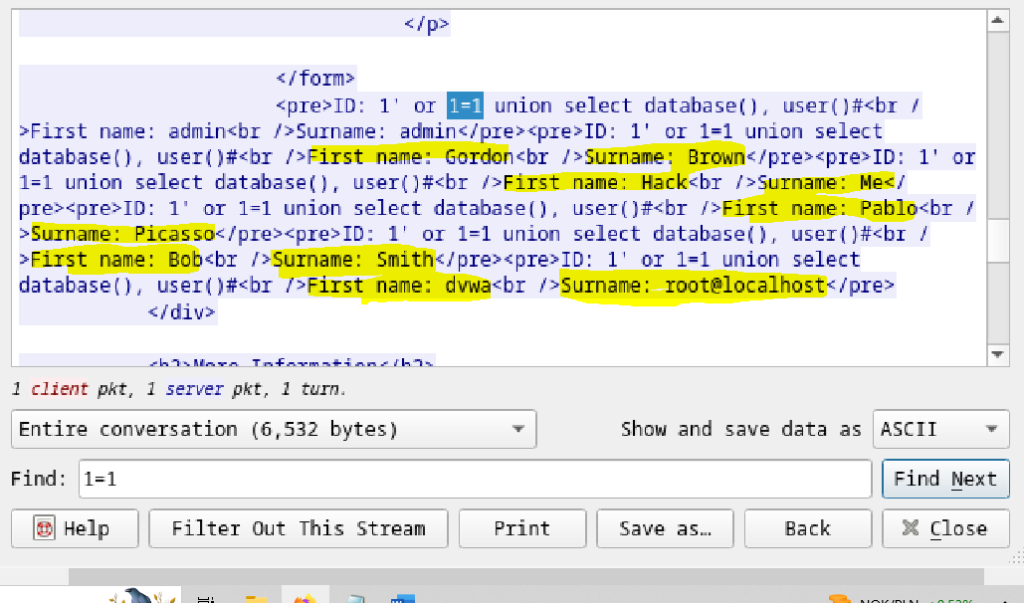
Jak widzimy, atakującemu udało się pozyskać dane First Name i Surname użytkowników naszej aplikacji webowej, co jest niezaprzeczalnym dowodem, że niestety udało mu się wykonać atak SQL injection skuteczne poprzez wstrzyknięcie fragmentu zapytania SQL w parametrze id o treści: 1’ or 1=1 union select database(), user() #.
Faza ograniczania strat, odcięcia atakującego i odzyskiwania
W tej fazie, gdy wiemy, że padliśmy ofiarą ataku, musimy natychmiastowo przerwać dalsze działania atakującego celem ograniczenia strat dla naszej organizacji (a raczej niedopuszczenia do powiększania się tych strat) a także przywrócić aplikację (o ile atakujący uderzył również w integralność lub dostępność naszego systemu) do pierwotnej postaci.
W analizowanym przez nas przypadku, gdyby atakujący nadal był w trakcie ataku, należałoby go jakkolwiek zbanować, aby nie miał możliwości dalszego ataku naszej aplikacji.
Aktywność post- incydentowa
Jest to niewyobrażalnie ważna faza! Dlaczego? Jak to się mówi, ludzi można ogólnie podzielić na optymistów i pesymistów. Pesymiści to są ci, którzy widzą zagrożenia w szansie, natomiast optymiści to ci, którzy widzą szansę w zagrożeniu. W kontekście incydentów warto być jednak tymi drugimi, ponieważ jeżeli incydent już się wydarzył (jakkolwiek by nie był przykry), to można jeszcze wydobyć wartość dla siebie i naszej organizacji poprzez wyciągnięcie wniosków z tej lekcji, którą dali nam atakujący. Jak to zostało napisane na samym początku – „incydenty się zdarzały, zdarzają i zdarzać będą”, to są niestety współczesne realia, natomiast olbrzymim zaniedbaniem byłoby dać się zaatakować ponownie w ten sam sposób, czyli nie odrobić lekcji z przeszłości, która daje nam szasnę na lepsze jutro.
W analizowanym przez nas przypadku, to co należałoby zrobić na pierwszy rzut oka, to oczywiście skopiować system, na którym jest zaatakowana aplikacja, a następnie wdrożyć walidację i/lub parametryzację w polu id a następnie przetesować czy rzeczywiście udaremni ona następne próby SQL Injection.



Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.