
W percepcji (mam nadzieję) administratorów, sztuczna inteligencja w kontekście cyberbezpieczeństwa przestaje być już magicznym przyciskiem i staje się narzędziem inżynierskim, którego wartość zależy w olbrzymiej mierze od jakości danych, architektury oraz sposobu wdrożenia.
W tym artykule pokażemy:
- Dlaczego jakość danych ma większe znaczenie niż sam model,
- Jak działa pipeline AI w praktyce,
- Jakie są techniczne trade-offy między on-prem a cloud,
- Jak przygotować środowisko, żeby modele działały stabilnie i dawały realną wartość.
Dlaczego jakość danych jest ważniejsza niż model (!)
To co bardzo istotne to fakt, że modele Machine Learningowe uczą się na danych. To nie jest tak, że modele te ot tak rozumieją jak działa atak hakerski. Nawet najlepszy model jest bezużyteczny, jeśli dane są złe, niskiej jakości, niespójne lub niekompletne.
Garbage in / garbage out
Jeśli model ML będzie uczył się na śmieciowych danych, to będzie również wyrzucał śmieciowe wyniki. To jest jak z ludźmi – jeśli mamy notatki które są liche, wówczas nasza wiedza, którą z nich wyniesiemy również będzie licha.
Typowe problemy z danymi:
- Różne strefy czasowe i brak synchronizacji NTP,
- Logi w różnych formatach (firewall, IDS, aplikacje, systemy operacyjne),
- Brak identyfikatorów sesji, NAT, logi anonimowe,
- Brak kontekstu biznesowego.
Jeśli model widzi tylko liczby (IP, port, timestamp), to nie potrafi ocenić, czy jakieś zachowanie w Twojej sieci jest normalne czy nie.
Normalizacja logów
Uczenie maszynowe (ML) działa na liczbach i kategoriach, a nie na tekstach. Logi muszą być ujednolicone.
Znów odnosząc się do analogii z życia wziętej – jeśli nasze notatki są częściowo po polsku, częściowo po angielsku, częściowo po węgiersku a reszta po chińsku, to nasz proces uczenia może być relatywnie trudny. 🙂
Przykład:
Firewall: „login failed”
App: „authentication error”
System: „auth_failure”
Po normalizacji: wszystkie trzy zdarzenia skategoryzowane są jako jedno zdarzenie typu login_failed.
Enrichment danych
Jest to ciągły proces rozszerzania i udoskonalania posiadanych już zbiorów danych. Bez kontekstu modele są ślepe. Enrichment pozwala AI „widzieć środowisko”.
Przykładowo:
- AD / LDAP: rola użytkownika, grupa, dostęp,
- CMDB: krytyczność systemu, środowisko (prod/dev/test), owner,
- Threat intel: reputacja IP, znane zagrożenia, geolokalizacja.
Feature engineering
Najważniejsze decyzje w ML są podejmowane na podstawie dobrze dobranych cech.
| Feature | Opis |
| failed_logins/user/hour | liczba nieudanych logów użytkownika |
| outbound_bytes/host/hour | ilość wychodzących danych z hosta |
| unique_dest_ips/host | liczba unikalnych IP docelowych |
| session_duration_avg | średni czas trwania sesji |
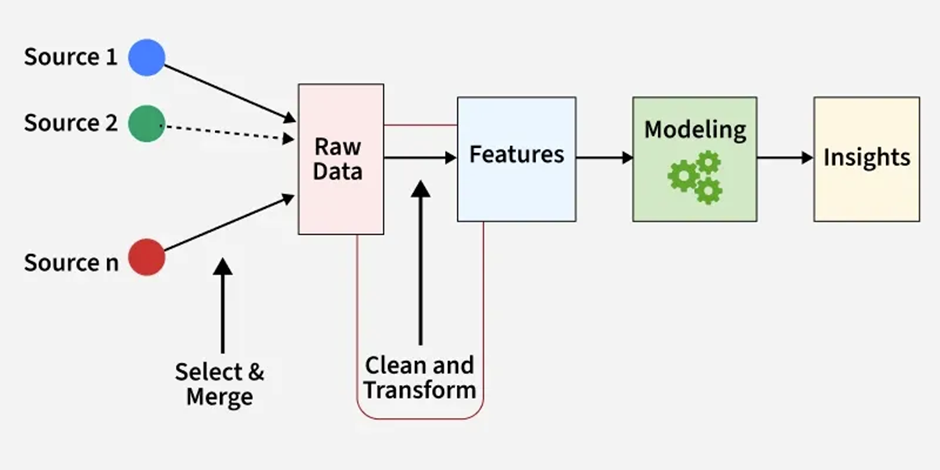
Jak działa feature engineering w Machine Learningu.
Feedback loop – retraining
Czym byłaby nauka bez feedbacku? Byłaby prawdopodobnie chodzeniem po omacku. Każdy z nas, prawdopodobnie, doświadczył sytuacji gdy wydawało mu się, że zrozumiał dane zagadnienie ale weryfikacja była jednak bolesna, bowiem ujawniała że jedynie nam się wydawało. Bez feedbacku model ML szybko się zestarzeje (drift) oraz będzie coraz mniej wartościowy.
Przykłady dobrych praktyk:
- Analityk SOC oznacza False Positives / True Positives
- Model uczy się na nowych/zaktualizowanych danych
- Scoring alertów jest weryfikowany i poprawiany na bieżąco.

Gdzie AI realnie działa – techniczne przykłady
Teraz, będąc już uzbrojonym w podstawowe zagadnienia, przechodzimy od teorii do praktyki – gdzie AI naprawdę przynosi wartość w codziennej pracy admina.
Detekcja anomalii
AI świetnie wykrywa nietypowe zachowania w ruchu sieciowym (oczywiście przy założeniu, że model był trenowany na wartościowych danych), szczególnie w dużych środowiskach.
Features / technika:
- liczba sesji na jednostkę czasu,
- średni czas trwania połączenia,
- liczba unikalnych portów,
- entropia IP/portów.
Modele: Isolation Forest, k-means, autoencoders.
Ograniczenia: Low-and-slow attacks mogą pozostać niewykryte (!).
Diagram pipeline:
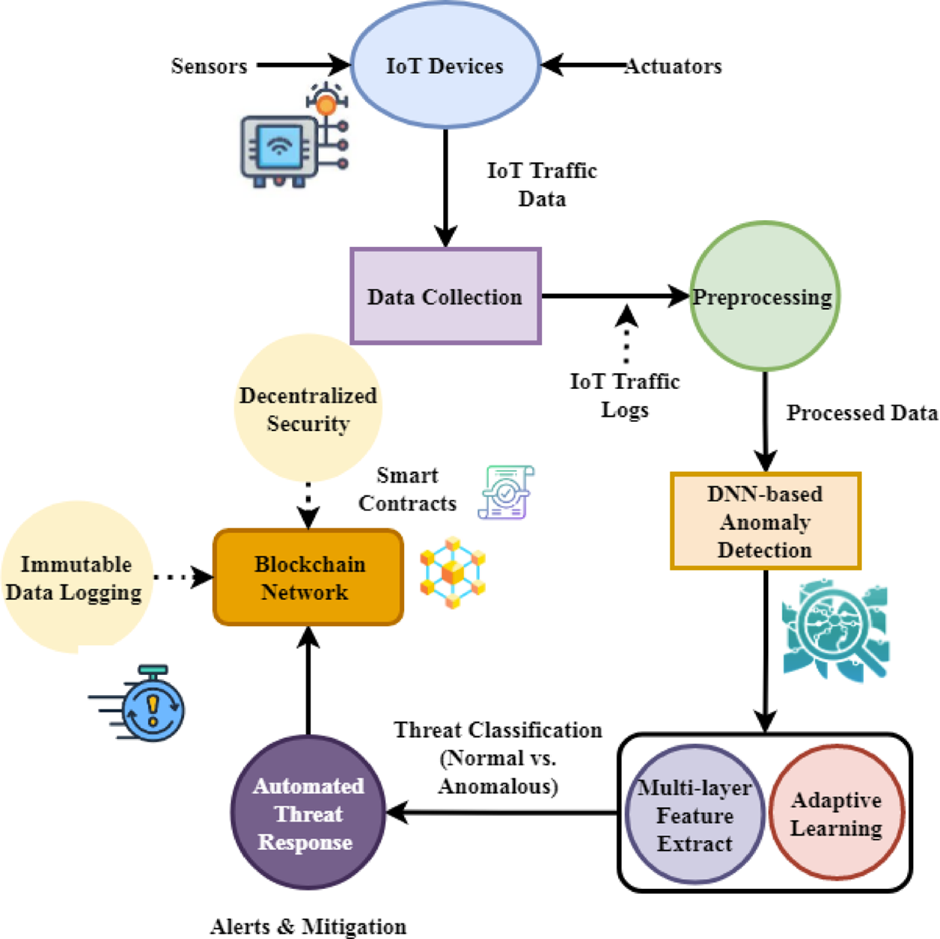
Analiza logów
Surowe logi w enterprise są nieustrukturyzowane i niestandardowe. ML pozwala:
- grupować podobne logi,
- wykrywać nowe wzorce,
- flagować odchylenia od baseline’u.
Techniki: log clustering, sequence modeling, statistical baselining.
Poniżej znajduje się grafika obrazująca log clustering.
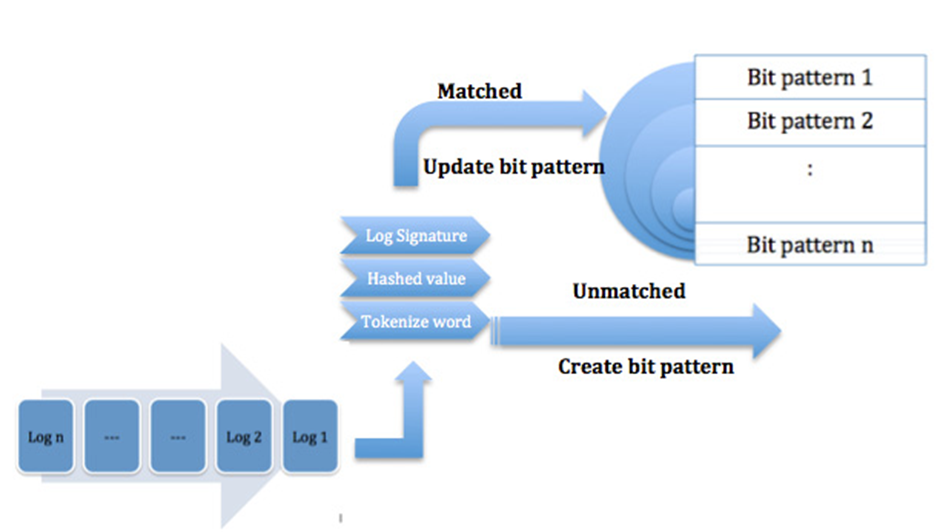
Alert triage
AI nie zastępuje analityków SOC – pomaga skupić się na najważniejszych alertach.
- Korelacja alertów z SIEM, EDR, NDR,
- Scoring ryzyka,
- Grupowanie alertów w incydenty.
Przykład alert triage:
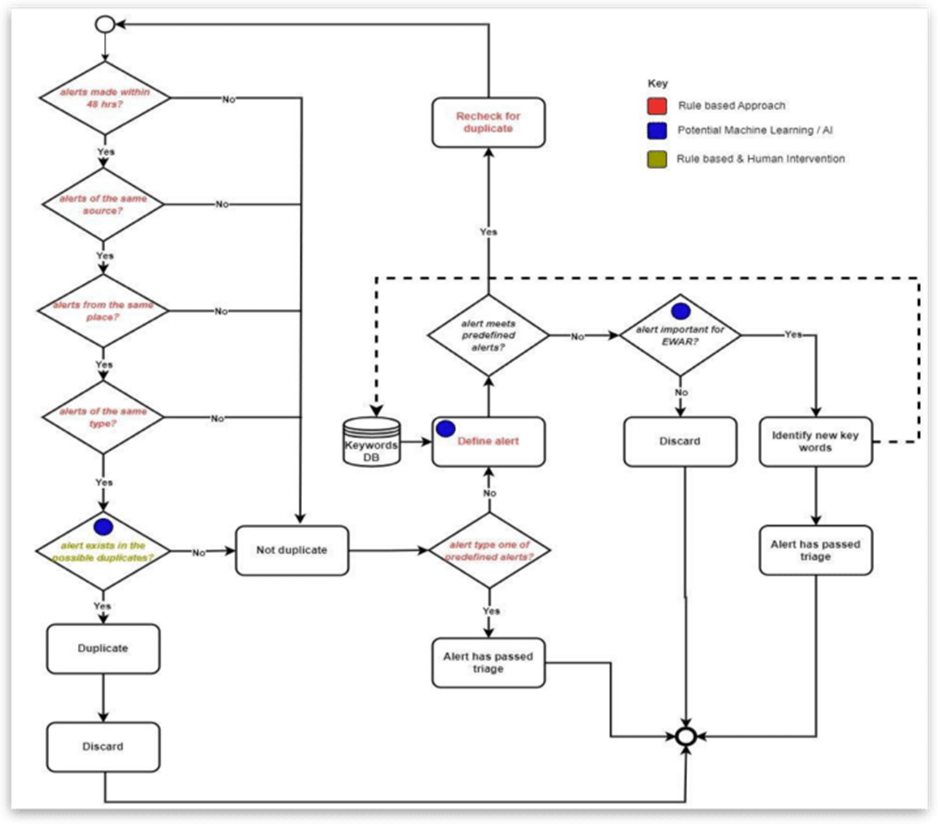
UEBA – profilowanie behawioralne
Modele budują baseline zachowań użytkowników i hostów. Alert powstaje, jeśli obserwowane zachowanie odbiega od normy.
Przykłady:
- Nietypowe loginy
- Nowe lokalizacje
- Wzrost outbound traffic


Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.