
W dzisiejszym artykule z serii skalowanie infrastruktury przedstawię prosty sposób na replikowanie danych zgromadzonych w bazie MySQL (silniki MySQL, MariaDB, Percona w tym zakresie działa podobnie więc mechanizm będzie podobny).
Dlaczego warto replikować bazę danych? Zreplikowana baza to większe bezpieczeństwo, większa niezawodność – a w przypadku systemów, które potrafią oddzielać np. odczyty od zapisów – także i podniesienie wydajności. Replikacja z pewnością wiele daje, ale nie powinno się jej traktować jak zamiennik kopii bezpieczeństwa, bowiem wszystko co zostanie zrobione na serwerze głównym, przeniesie się na wszystkie pozostałe repliki, więc jeśli wykonany zostanie DROP na bazie, replikacja przed nim nie chroni, jeśli jest zsynchronizowana w czasie i nie posiada opóźnienia w synchronizacji (powstałego w związku z dużą ilością zapytań lub po ustawieniu opcji opóźniania). Z drugiej strony, jeśli awarii ulegnie serwer główny, dzięki replice można w stosunkowo krótkim czasie przełączyć ruch (kilka kliknięć) na serwer zapasowy i przywrócić system do działania.
Czym jest replikacja?
Jest to konfiguracja, w której mamy serwer główny – master oraz serwer zapasowy – slave, gdzie mamy jeden serwer główny oraz jeden lub więcej serwerów replik. W tej konfiguracji zapisujemy dane i zmieniamy je na serwerze głównym, a serwery replikujące aktualizują się automatycznie.
Plusy:
- większa niezawodność środowiska i odporność na awarie;
- wzrost wydajności poprzez możliwość rozdzielenia zapisów i odczytów aplikacji na różne serwery;
- możliwość wykonywania kopii bezpieczeństwa z serwera zapasowego bez wpływu na wydajność serwera głównego;
- replikacja może być prowadzona także na serwery w innej lokalizacji.
Minusy:
- nie chroni przed operacjami typu DROP;
- opóźnienie z jakim rekordy są odtwarzane na serwerze repliki;
- konieczność przebudowy aplikacji do odczytów i zapisów z różnych serwerów;
- replikacja wykonuje także błędne operacje, przez co może przestać działać w każdej chwili (konieczne jest monitorowanie replikacji).
Metody replikacji
- SBR (statement-based replication) – w trybie tym serwer master zapisuje w pliku wszystkie operacje jakie wykonał. Jest to najszybsza i najbardziej wydajna metoda, bowiem serwer zapisuje zapytania jakie zostały wykonane, a następnie serwer repliki odczytuje je i wykonuje u siebie. Problem w tym, że w przypadku bardziej złożonych zapytań samo zapisanie zapytania może nie wystarczyć. W przypadku użycia funkcji RANDOM wynik na serwerze głównym i zapasowym będzie różny.
- RBR (row-based replication) – w trybie tym serwer master zapisuje do plików binarnych (bin logów) wyniki działań jakie wykonał na serwerze. Zapisywana jest tutaj informacja o tym, jaki rekord został zmieniony w jaki sposób. Jest to rozwiązanie problemów metody SBR, ale jednocześnie znacznie wolniejsze i generujące dużo więcej danych pomiędzy serwerami.
- MFL (mixed-format logging) – jest to połączenie metody SBR i RBR. W metodzie tej w większości przypadków logowane są zapytania, podobnie jak w przypadku metody SBR, ale dla bardziej złożonych zapytań, które mogą zwrócić nieoczekiwany wynik lub różny, wykorzystywana jest metoda RBR.
Przygotowanie środowiska
Znamy już zarys teorii o replikacji baz danych MySQL, przejdźmy do konfiguracji środowiska. Na potrzeby niniejszego artykułu przygotowałem dwa serwery, połączone ze sobą siecią lokalną, interfejsy zewnętrzne zostały wyłączone.
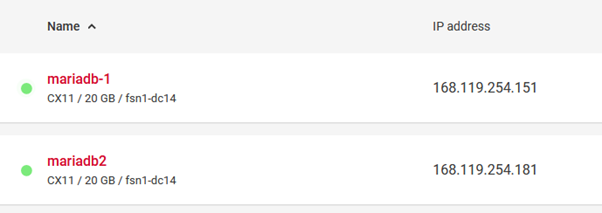
Na obu serwerach skorzystałem z pakietu: Ver 15.1 Distrib 10.3.25-MariaDB.
Serwer: mariadb-1 – adres IP lokalny: 10.0.0.2
Serwer: mariadb-2 – adres IP lokalny: 10.0.0.3
Konfiguracja:
Z ważniejszych rzeczy jakie musimy ustawić na obu serwerach (zmieniając adres IP oraz numer serwera)
Serwer: mariadb-1:
bind-address = 10.0.0.2
server-id = 1
log-bin = /var/log/mysql/mariadb-bin
binlog_format = mixed
max_binlog_size = 100M
Serwer: mariadb-2:
bind-address = 10.0.0.3
server-id = 2
Reszta parametrów to kwestia optymalizacji, dla uruchomienia samej replikacji, spokojnie wystarczy.
Uruchomienie replikacji
Na serwerze “mariadb-1” dodajemy użytkownika, który będzie odpowiedzialny za replikację i nadajemy mu odpowiednie uprawnienia:
CREATE USER 'replikacja’@’10.0.0.%’ IDENTIFIED BY 'haslo’;
GRANT REPLICATION SLAVE ON *.* TO 'replikacja’@’10.0.0.%’ IDENTIFIED BY 'haslo’;

Na serwerze mariadb-1 wykonujemy polecenie blokujące możliwość modyfikowania danych, dzięki czemu replikacja i dane będą konsystentne.
FLUSH TABLES WITH READ LOCK;
Sprawdzamy status serwera głównego:
SHOW MASTER STATUS;
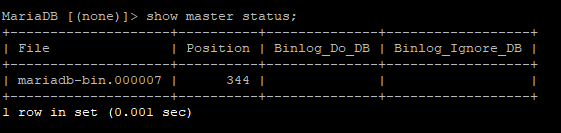
Zapisujemy wartości “File” oraz “Position”, będą nam później potrzebne.
Zatrzymujemy serwer MySQL.
systemctl stop mariadb.service

Na drugim serwerze mariadb-2 mamy zainstalowaną usługę, ale wyłączony serwer MySQL.
Serwer: mariadb-1
mv /var/lib/mysql /var/lib/mysql-old
mkdir -p /var/lib/mysql
rsync -avz /var/lib/mysql/* -e „ssh -p 10122” root@10.0.0.3:/var/lib/mysql/
UWAGA: Możemy także po wykonaniu FLUSH’a zrobić mysqldump wszystkich danych, przesłać plik dump’a i zaimportować na serwerze replikacji. Technicznie nie ma to większego znaczenia czy zsynchronizujemy pliki rsynkiem czy dumpem.
Serwer: mariadb-2
chown -R mysql:mysql /var/lib/mysql
Kiedy mamy już wysłane wszystkie dane, możemy wystartować na obu serwerach usługi.
Serwer: mariadb-1
systemctl start mariadb.service
Serwer: mariadb-2
systemctl start mariadb.service
Logujemy się do serwera MySQL:
mysql -u root -p
Ustawiamy replikację zgodnie z danymi konta, które wcześniej utworzyliśmy:
CHANGE MASTER TO MASTER_HOST=’10.0.0.2′, MASTER_USER=’replikacja’, MASTER_PASSWORD=’haslo’, MASTER_PORT=3306, MASTER_LOG_FILE=’mariadb-bin.000007′, MASTER_LOG_POS=344, MASTER_CONNECT_RETRY=10;
START SLAVE;
SHOW SLAVE STATUS \G;
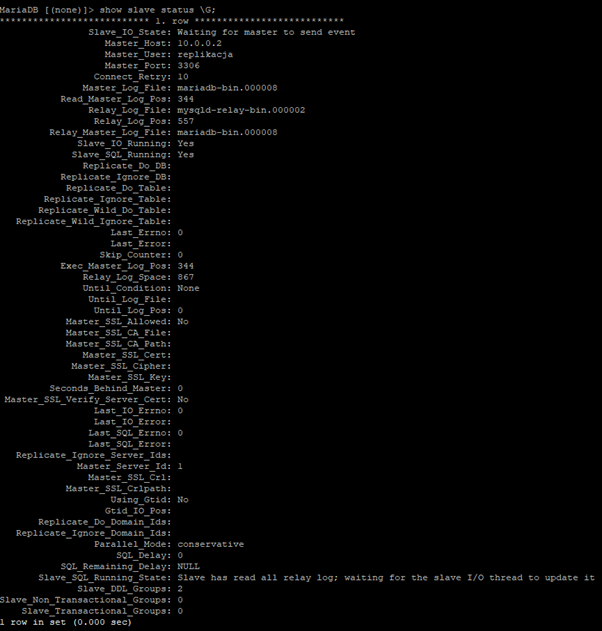
Testowanie replikacji
Po uruchomieniu replikacji sprawdźmy czy dane się zmieniają.
Na serwerach 1 i 2 wykonujemy, na przykład, sprawdzenie dostępnych baz:
show databases;
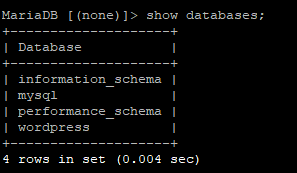
Na obu serwerach powinniśmy mieć te dane bazy, dane.
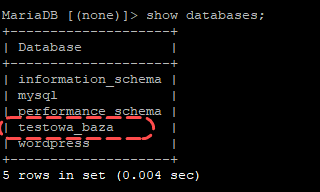
Dodajemy na serwerze głównym nową bazę:
MariaDB [(none)]> create database testowa_baza;
Query OK, 1 row affected (0.004 sec)
Zarówno na serwerze głównym, jak i na replikacji powinniśmy mieć je dodane.
Podsumowanie
Przedstawiony tutaj mechanizm replikacji ma wiele zalet, ale też i kilka wad (choć nie są one istotne biorąc pod uwagę więcej zalet).
Istotną zaletą na pewno jest podniesienie wydajności naszej infrastruktury. Jeśli aplikacja posiada możliwość odczytywania i zapisywania na różne serwery, to z pewnością podniesie to wydajność. Wielu użytkowników interesuje szybki dostęp do zasobów strony i odczytywanie z niej informacji. Mając do dyspozycji kilka serwerów replik, możemy tak rozproszyć ruch, że aplikacja będzie działać o wiele szybciej niż w tradycyjnej konfiguracji z jednym serwerem. Ilość replik wpływa, rzecz jasna, na koszty, ale zawsze warto zadać sobie pytanie ile warty i jak kosztowny może być dla nas przestój związany z awarią.
Do zalet replikacji należy także możliwość wykonywania kopii bezpieczeństwa z serwera kopii, które nie obciążają serwera głównego. Z drugiej strony, serwer replikacji nie chroni jednak przed poleceniami kasującymi. Jeśli zostaną one wykonane na głównym serwerze, przelecą też na serwer zapasowy. Pewnym rozwiązaniem może być ustawienie flagi DELAY dla replikacji, gdzie dopiero po upływie pewnego czasu zmiany zostaną wykonane na serwerze repliki, ale przez ten czas opóźnienia nie będziemy mieć na nim danych 1:1 z serwerem głównym. Można także wykorzystać możliwość COMMITów zmian wprowadzone w wersji MySQL 5.5, polegające na tym, że dopiero po akceptacji zmian zostaną one wykonane. Ma to też swoje wady.
Mimo wszystko, jeśli zależy nam na wyższej niezawodności i dostępności naszej infrastruktury i aplikacji, warto korzystać z mechanizmów replikujących.




Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.