
Czym jest Error log?
Dziennik błędów to przeważnie plik tekstowy, w którym znajdują się zarejestrowane aktywności, powodujące różnego rodzaju błędy. Innymi słowy jest to plik zawierający informacje o niepożądanej aktywności użytkownika.
Jakie może to mieć praktyczne znaczenie w kontekście wykrywania potencjalnych ataków z punktu widzenia administratora danego systemu?
Musimy mieć świadomość, że złośliwe akcje wykonywane przez atakujących nie muszą także być aktywnością, która jest niepożądana z punktu widzenia logiki aplikacji czy systemu.
Zilustrować tę sytuację można przykładem aplikacji, która nadaje każdemu użytkownikowi uprawnienia do tworzenia dodatkowych kont w systemie (czyli ogólnie mówiąc aplikacja dająca nadmiarowe uprawnienia dla danego użytkownika).
W momencie stworzenia kilku dodatkowych kont, które mogą stanowić potencjalny backdoor, dziennik błędów nie będzie zawierał wpisów z tej akcji, ponieważ ta akcja nie jest zabronioną z punktu widzenia logiki takiej aplikacji.
Zakładając sytuację podczas której uprawnienia użytkowników danego systemu zgodne są z zasadami need to know oraz least privilegesnależałoby się spodziewać, że dziennik błędów może zawierać informacje związane z próbami uzyskania nieautoryzowanego dostępu do danego zasobu tego systemu.
Wpisy umieszczone w dzienniku błędów mogą wskazywać działanie np. automatycznych narzędzi, które przeszukują pre-definiowane ścieżki (używane przez to narzędzie) w systemie.
Poniżej znajduje się zrzut ekranu, który obrazuje czytelnikowi, jak wyglądają takie wpisy:

Jest to zrzut z dziennika błędów pochodzącego z serwera webowego apache.
Od lewej znajdują się (podobnie jak w przypadku dziennika zdarzeń) dane dotyczące daty oraz godziny zalogowania danego błędu. Co istotne, jest to data i godzina zalogowania błędu, która pochodzi ze skonfigurowanej lokalnie (na serwerze na którym zainstalowany jest serwer webowy apache) daty oraz strefy czasowej.
Po lokalnej dacie i czasie zalogowania błędu znajduje się kategoria wpisu, czyli w pierwszej linii jest to notyfikacja, pozostałe linie wskazują na kategorię wpisu, która określa błąd. Dalej znajduje się adres IP użytkownika, który wyzwolił akcję, powodującą dany błąd. Następnie jest informacja zwrotna, która została przekazana do owego użytkownika. Na końcu (pierwsza kolumna od prawej) znajduje się adres do zasobu, który szukał użytkownik a którego nie udało mu się znaleźć.
W przypadku skanowania automatycznym narzędziem, linii w dzienniku błędów będzie znacznie więcej dla każdego jednego takiego skanowania. Poniżej znajduje się fragment zrzutu ekranu z takiej aktywności.
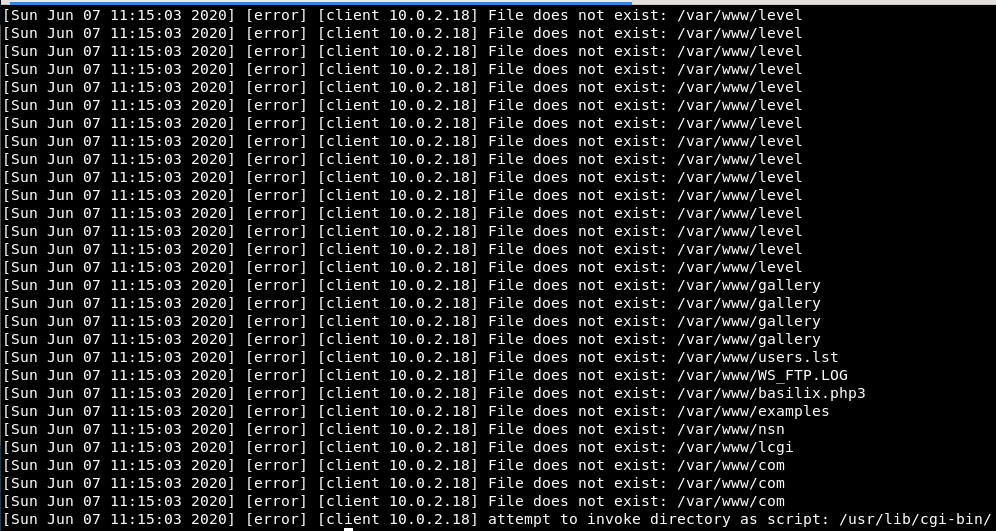
Co wskazuje, że było to skanowanie automatyczne jakimś narzędziem? Wystarczy zwrócić uwagę na godzinę wykonania dużej ilości zapytań.
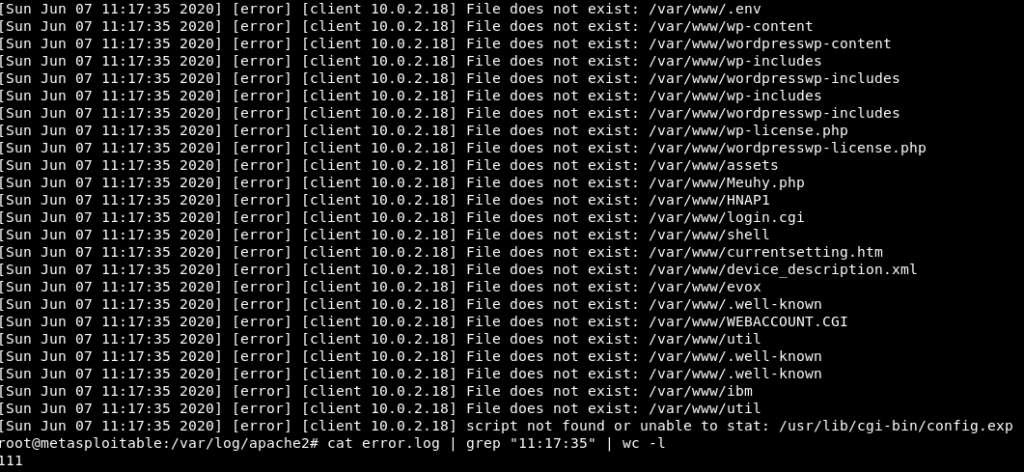
Dla godziny lokalnej 11:17:35 dziennik błędów zawiera 111 wpisów. Czyli w konkretnej sekundzie automatyczny skaner wygenerował 111 wpisów w error logu.



Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.