
Repozytorium kodu jest jednym z kluczowych elementów każdej infrastruktury dedykowanej do automatyzacji zadań (pisałem już o tym w moim wcześniejszym artykule):
- Stanowi podstawę bezpieczeństwa dla kodu – niezależnie czy to mały skrypt w bash-u, pliki konfiguracyjne, szablony modeli danych, playbook Ansible czy rozbudowana własna aplikacja Twoja firma potrzebuje scentralizowanego systemu, który pozwoli w bezpieczny sposób przechowywać aktualne ich wersje oraz zarządzać dostępem do nich.
- Inne aplikacje powinny pobierać na bieżąco kod z centralnego repozytorium.
- Jest elementem systemu kontroli zmian, aby zapewnić zgodność z firmowymi normami.
- Jest ważnym elementem pracy grupowej, w której wiele osób z różnych zespołów tworzy jeden produkt.
Każda firma powinna mieć własny system do pracy nad projektami.
Jeżeli chcemy stworzyć publiczny projekt to zazwyczaj robimy to w serwisie GitHub albo GitLab. Każdy z nich pozwala też na utrzymanie niewielkiej liczby prywatnych projektów. Komercyjne konta w tych serwisach mogą być wystarczające dla wielu firm, choć nie dla każdego rodzaju projektu. W przypadku projektów związanych z automatyzacją wskazane jest uruchomienie repozytorium wewnątrz własnej infrastruktury. Istnieje szereg komercyjnych projektów tego typu, ja jednak na początek polecam Ci zapoznanie się z GitLabem, który oprócz działania w chmurze możemy zainstalować na własnych serwerach. Jego darmowa wersja powinna mieć wystarczająco funkcjonalności na początek przygody z automatyzacją. W razie potrzeby możemy zawsze rozważyć dokupienie jednej z komercyjnych licencji.
GitLab do działania potrzebuje trzech komponentów:
- Oprogramowania GitLab
- Relacyjnej bazy danych PostgreSQL
- Bazy danych typu klucz-wartość Redis
Wszystkie te komponenty możemy zainstalować jako natywne usługi systemu operacyjnego Linux. Wspierane dystrybucje to między innymi Ubuntu, Debian, CentOS czy Redhat EL. Do działania potrzebuje minimum 2 vCPU oraz 8GB pamięci RAM. Wymagania rosną wraz z liczbą użytkowników systemu. Ponadto nasz system musi mieć zainstalowane oprogramowanie Ruby, Go, Node,js czy Git w wersjach wymaganych przez GitLab. Utrzymanie takiego środowiska może nie być proste. Dlatego ja preferuję instalację w kontenerach Dockera.
Podstawą naszej pracy jest system Linux z działającym Dockerem. Na początek wystarczy pojedyncza instancja lub klaster Swarm składający się z pojedynczego węzła. Obrazy GitLaba dostępne są w publicznym repozytorium Dockera pod adresem https://hub.docker.com/r/gitlab/gitlab-ce. Uruchamianie wspomnianych trzech komponentów zautomatyzujemy za pomocą Docker Compose, którego plik konfiguracyjny znajdziesz na moim repozytorium GitHub-a.
Infrastruktura
GitLab do prawidłowego działania potrzebuje pomiędzy kontenerami sieci, która będzie łączyć ze sobą wspomniane trzy aplikacje. Docker Compose taką sieć sam tworzy dla każdego uruchamianego za jego pomocą projektu nadając jej unikalną losową nazwę. Ja jednak wolę mieć pewną kontrolę nad nazewnictwem obiektów, dlatego dodałem własną sieć o nazwie gitlab i podłączyłem ją do wszystkich trzech kontenerów.
gitlab:
external: no
Kolejnym niezbędnym elementem infrastruktury są wolumeny, które przypisujemy do kontenerów. To w nich aplikacje będą zapisywały swoje pliki. W środowisku testowym wystarczy, że skorzystamy z lokalnych wolumenów tak jak to ma miejsce w załączonym pliku. Możemy także podłączyć katalog bezpośrednio z naszego systemu operacyjnego. Pamiętajmy, że wolumeny raz utworzone nie są usuwane wraz z kontenerami, dzięki czemu przetrwają awarię, planowaną przerwę lub aktualizację. Gdybyśmy ich nie zdefiniowali to każde usunięcie kontenera wiązałoby się także z usunięciem wszystkich plików niezbędnych do pracy GitLaba.
Aplikacje
Nowe główne wersje GitLaba wychodzą raz na miesiąc. Pomiędzy tymi wydaniami publikowane są wydania zawierające poprawki błędów czy łatające wykryte luki bezpieczeństwa. Kontener samego GitLaba będziemy zatem dość często aktualizować, dlatego w definicji obrazu kontenera używamy tagu „latest”. PostgreSQL i Redis nie chcemy aktualizować co chwilę – może to rodzić spore problemy, gdy aktualizacja wymaga manualnych czynności od administratora, a w przypadku błędów może nawet skutkować utratą danych. Dlatego w ich przypadku wskazujemy konkretne wersje obrazu, które chcemy używać.
W załączonym pliku zostawiłem domyślne nazwy użytkowników, hasła i inne parametry. Przekazujemy je do kontenerów jako zmienne środowiskowe. W środowiskach produkcyjnych nie powinniśmy korzystać z tych domyślnych wartości.
Do poprawnego działania musi być zapewnione nie tylko połączenie pomiędzy kontenerami (to zapewnia Docker), ale też przekazane parametry połączenia takie jak choćby loginy, hasła czy porty usług wewnętrznych. Moja konfiguracja nadaje się co najwyżej do uruchomienia w firmowym labie, gdyż parametry te są umieszczone jawnym tekstem jako zmienne środowiskowe przypisane do odpowiednich kontenerów. Zwróćmy uwagę na kilka z nich.
Do kontenera „gitlab” przekazujemy zmienną środowiskową o nazwie GITLAB_OMNIBUS_CONFIG, która składa się z wielu parametrów. Większości z nich nie zmieniamy, chyba, że dokonaliśmy zmian w parametrach dostępu choćby do bazy danych. Parametr „external_url” zapisany w zmiennej musi mieć taką samą nazwę jak „hostname” z definicji kontenera. Ponadto do gitlab_rails[’gitlab_shell_ssh_port’] przypisujemy taką samą wartość jak adres zewnętrznego portu usługi SSH. W naszym przypadku jest to 30022, gdyż za pomocą definicji „30022:22” w sekcji „ports” ustawień port 22 kontenera przypisaliśmy do portu 30022 systemu operacyjnego. W definicji kontenera z bazą danych ustawiamy trzy zmienne, którym przypisujemy odpowiednio login, hasło i nazwę bazy dla tworzonej usługi.
Uruchomienie
Aby uruchomić zdefiniowane kontenery wydajemy w katalogu, w którym zapisaliśmy plik docker-compose.yml polecenie docker-compose up -d. Zostaną wtedy pobrane wskazane wersje obrazów poszczególnych kontenerów, stworzone wolumeny i sieć. Możemy też pominąć parametr „-d” i obserwować na bieżąco logi z uruchamiania usług. Poleceniem docker ps wyświetlimy stan poszczególnych kontenerów. Gdy przy kontenerze „gitlab” pojawi się status „(healthy)” znaczy, że uruchomienie powiodło się i główny kontener działa poprawnie.
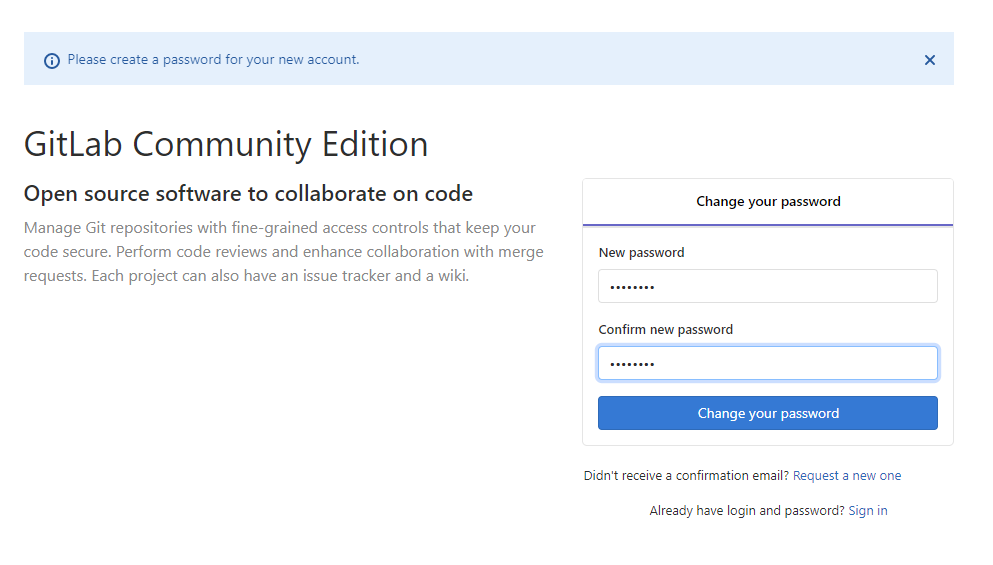
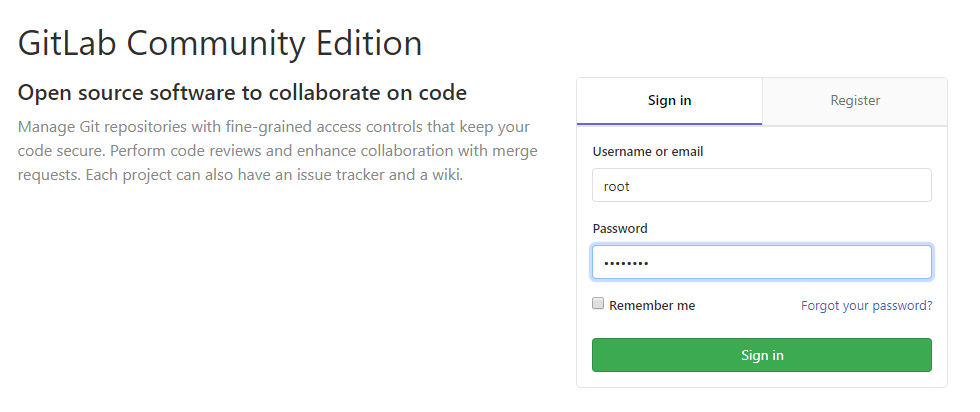
Do stworzonej instancji GitLaba łączymy się przeglądarką. Musimy zaakceptować certyfikat typu self-signed. Przy pierwszym uruchomieniu zostaniemy poproszeni o utworzenie hasła dla głównego użytkownika systemu. Ma on identyfikator „root”. Po poprawnym zalogowaniu możemy tworzyć kolejnych użytkowników, projekty oraz zmieniać ustawienia pracy GitLaba.



Wszystkie polecenia warto wpisać w znacznikach code, które można odpowiednio wyróżnić. Zwiększy to czytelność we wpisie. Pozdrawiam