
W dzisiejszych czasach dane stanowią jeden z najważniejszych zasobów każdej organizacji. Niezależnie od tego, czy prowadzimy małą firmę, czy zarządzamy ogromnym przedsiębiorstwem, ochrona danych przed utratą jest kluczowa dla ciągłości biznesowej. Nawet najbardziej niezawodne systemy mogą ulec awariom, błędom użytkownika czy atakom złośliwego oprogramowania. Właśnie dlatego tworzenie regularnych kopii zapasowych (backupów) jest nieodzownym elementem każdej strategii zarządzania danymi. Na łamach Władców pojawił się już jakiś czas temu wpis o kopiach, lecz w tym konkretnym artykule skupię się na odpowiedzi na pytanie o różnice między kopią deduplikowaną, przyrostową i różnicową. Zrozumienie tych pojęć pozwoli na lepsze dobranie odpowiedniego rozwiązania do specyficznych potrzeb i wymagań każdej organizacji.
Typy backupów
Backup deduplikowany
Deduplikacja danych to technika mająca na celu zmniejszenie ilości przechowywanych danych poprzez eliminację duplikatów. W kontekście backupu, deduplikacja polega na przechowywaniu tylko unikalnych bloków danych, a nie całych plików. Na przykład, jeśli wiele plików zawiera te same fragmenty danych, deduplikacja zapisze tylko jeden egzemplarz danego fragmentu, a reszta będzie odwoływać się do tego samego bloku. Dzięki temu oszczędzamy miejsce na nośnikach backupowych i redukujemy koszty przechowywania danych.
Backup przyrostowy
Backup przyrostowy jest jednym z najefektywniejszych sposobów tworzenia kopii zapasowych pod względem czasu i zasobów. To właśnie ten przykład omówię szerzej w tym artykule. Warto jednak znać wszystkie 3 najbardziej popularne rodzaje kopii zapasowych. Przywołany backup przyrostowy polega na zapisywaniu tylko tych danych, które zmieniły się od ostatniego utworzenia kopii – niezależnie od tego, czy był to backup pełny, różnicowy, czy przyrostowy. W praktyce oznacza to, że pierwszy backup przyrostowy jest niewielki, a kolejne zawierają tylko zmiany wprowadzone od momentu wykonania ostatniego backupu. Zalety tej metody to minimalna ilość danych do przeniesienia i przechowywania, co skutkuje szybszymi operacjami backupu.
Backup różnicowy
Backup różnicowy jest kompromisem między backupem pełnym a przyrostowym. Polega na zapisywaniu wszystkich zmian, które zaszły od momentu wykonania ostatniego backupu pełnego. W odróżnieniu od backupu przyrostowego, który zapisuje tylko zmiany od ostatniego backupu (czy to pełnego, czy przyrostowego), backup różnicowy rośnie wraz z każdą kolejną sesją, dopóki nie zostanie wykonana nowa kopia zapasowa. Choć backup różnicowy może zajmować więcej miejsca niż przyrostowy, jest łatwiejszy do przywrócenia, ponieważ wymaga jedynie ostatniego backupu pełnego oraz najnowszego backupu różnicowego.
BorgBackup – prosty i szybki, a do tego szyfrowany backup
Instalacja w systemie:
apt install borgbackup -y
Wybierzmy ścieżkę, repozytorium naszych kopii:
export BORG_REPO=/mnt/backup
Inicjalizujemy strukturę dla naszych kopii:
borg init –encryption=repokey $BORG_REPO
Włączmy od razu enkrypcję tych kopii. Będziemy mieli przy okazji z głowy kwestię szyfrowania backupów, które będziemy mogli wystawić od razu na nośnikach bez dodatkowych opcji. Borg potrafi szyfrować natywnie, więc skorzystajmy z tej opcji.
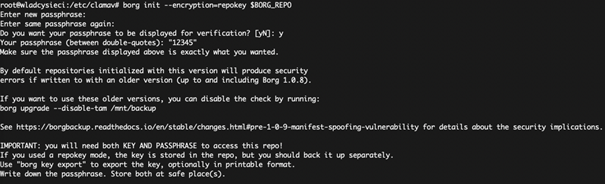
Warto w tym miejscu poradzić, aby wykonać kopię tej struktury w innym, bezpiecznym miejscu. Istnieje bowiem ryzyko, że w przypadku zagubienia struktury nie będzie możliwe odszyfrowanie kopii.
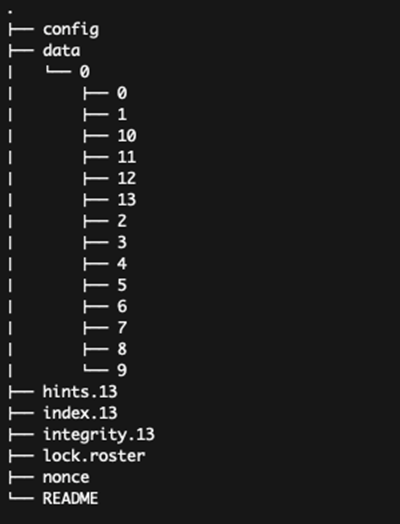
Po zainicjalizowaniu struktury w miejscu, gdzie będziemy trzymać nasze dane, pojawią się niezbędne dla Borga pliki:
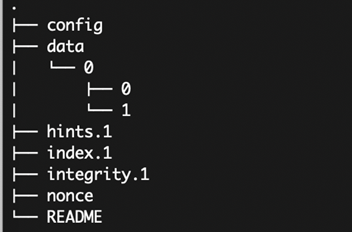
Nie wolno nam tu niczego zmienić czy usuwać – są to pliki z sumami, indeksy i inne potrzebne do działania ekosystemu Borga.
Tworzenie pełnej kopii na początek
W backupie przyrostowym musimy mieć jakiś punkt odniesienia. Takim punktem jest startowa kopia pełna. W naszym przypadku chcemy zachować dane z folderu /etc /home oraz /var.
borg create –progress –stats $BORG_REPO::initial-$(date +%Y-%m-%d) /etc /var /home
Po wykonaniu polecenia dostaniemy podsumowanie:
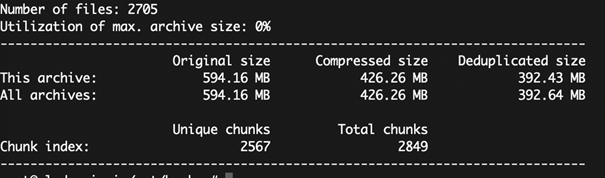
Tworzenie przyrostu dla kopii pełnej
borg create –progress –stats $BORG_REPO::incremental-$(date +%Y-%m-%d) /etc /var /home
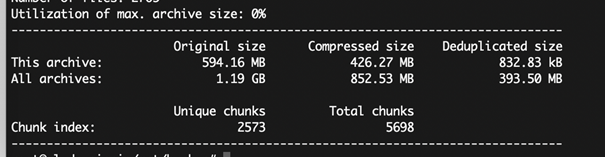
Jak widać, niewiele zmieniło się od ostatniego backup. Nie ma zatem potrzeby kopiowania wszystkich plików a jedynie zmian. Zapiszmy jednak zmian,ę np. na 1 GB.
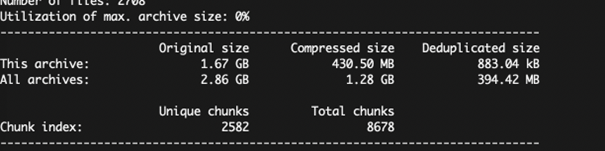
Jak widać, archiwum zwiększyło swoją objętość oryginalnie o 1 GB, ale dzięki kompresji Borg znacząco też zmniejszył rozmiar naszych plików.
Wyświetlanie listy kopii
Aby wyświetlić kopie, które znajdują się w naszym systemie, możemy skorzystać z polecenia list:
borg list $BORG_REPO
initial-2024-02-03 Mon, 2024-02-03 12:18:52 [ba5beab5c54d67d6ba51e69600a412840fbd62fb69958607a9380763e2ab9e57]
incremental-2024-02-03 Mon, 2024-02-03 12:20:22 [c8604ced1748817bf7cfc4ead11c7875b34b41bb68a19d4ed6952f71e9512787]
incremental-2024-02-03_12_22 Mon, 2024-02-03 12:22:39 [7c97ae13e91b82ca58f4f505b0fd0c2890ca9da7405e487c7e27b046a704b886]
Dostęp do danych
Istnieje kilka sposobów na odzyskanie konkretnego pliku z backupu borg. Jednym z nich jest zamontowanie katalogu kopii w systemie, tak samo jak robi się to z udziałami nfs czy cifs.
Aby móc zamontować backup jako folder, musimy dograć niezbędne biblioteki:
apt-get install python3-llfuse
mkdir /mnt/borg_mount
borg mount $BORG_REPO:: incremental-2024-02-03 /mnt/borg_mount

Możemy już w tej chwili przystąpić do odzyskiwania plików, folderów i innych, które są nam niezbędne. Jak widzimy, nie jest to skomplikowane zadanie. Warto jednak pamiętać o utrzymaniu porządku w nazwie oraz rozróżniać backup pełny od przyrostowego.
Po skończeniu pracy z systemem plików trzeba go obowiązkowo zamknąć – żeby cały czas pozostał bezpieczny i zaszyfrowany. Dlaczego? Ponieważ zamknięty backup nie daje możliwości podejrzenia plików i sprawdzenia co się w nim znajduje.
Wygląd zamkniętej kopii:
Podsumowanie
Zrozumienie trzech metod tworzenia kopii zapasowych jest niezbędne dla wyboru odpowiedniego rozwiązania, które zapewni bezpieczeństwo danych przy jednoczesnym optymalnym wykorzystaniu zasobów. Deduplikacja, backup przyrostowy i różnicowy to rodzaje kopii zapasowych, które mogą znacząco zmniejszyć koszty przechowywania danych oraz skrócić czas potrzebny na ich backup i odzyskiwanie. Wybór odpowiedniej metody zależy od specyfiki środowiska oraz potrzeb organizacji, jednak każda z tych technik stanowi ważny element kompleksowej strategii ochrony danych.




Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.