
W świecie Kubernetesa, networking nie jest jedynie cechą dodatkową – jest fundamentem, na którym zbudowana jest cała abstrakcja platformy. Biorąc pod uwagę, wieloletnie doświadczenie w budowaniu sieci i rozwiązań chmurowych oraz pracę z kontenerami od początku ich rozwoju, można stwierdzić, że zrozumienie sieci Kubernetesa jest kluczowe dla projektowania odpornych, bezpiecznych aplikacji. Te wszystkie zagadnienia ewoluują od czasu, kiedy kontenery w ogóle pojawiły się na rynku. W przeciwieństwie do tradycyjnych środowisk, gdzie aplikacje komunikują się ze stałymi adresami IP, Kubernetes wprowadza dynamiczny, efemeryczny i zdecentralizowany model sieciowy, w którym adresy IP są ulotne, a usługi są odkrywane, a nie konfigurowane na sztywno. Ten model jest zarówno największą siłą Kubernetesa, jak i źródłem największych wyzwań. Zostaną zagłębione mechanizmy, które umożliwiają płynną komunikację pomiędzy aplikacjami, od najniższego poziomu komunikacji między Podami, przez abstrakcję Service, po zaawansowane routingowanie warstwy aplikacji za pomocą Ingress Controller.
- IP-per-Pod
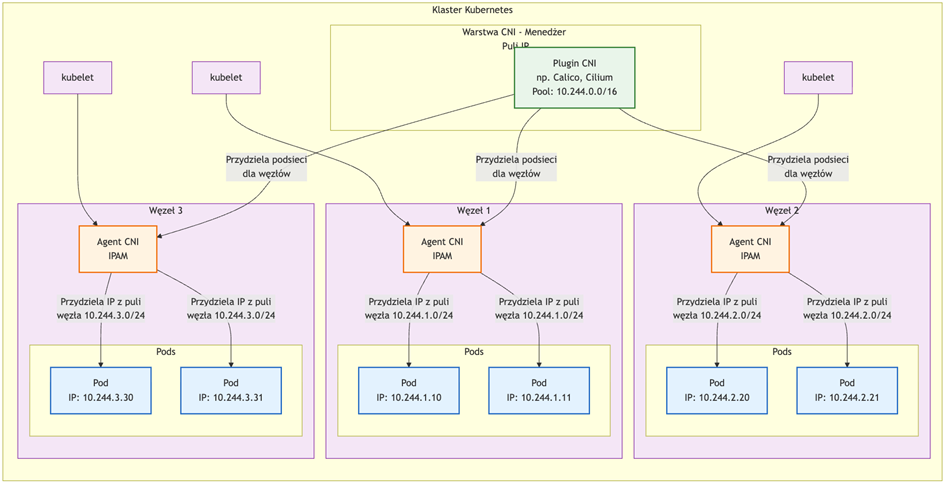
Fundamentalną zasadą sieciową Kubernetesa jest model „IP-per-Pod”. Każdy Pod, niezależnie od liczby kontenerów, otrzymuje jeden, unikalny adres IP z puli adresowej klastra. Wszystkie kontenery w ramach jednego Poda współdzielą tę samą przestrzeń sieciową (network namespace), co oznacza, że mogą komunikować się ze sobą za pomocą localhost.
Zalety:
- Spójność: Aplikacje wewnątrz Podów widzą się nawzajem na
localhost, upraszczając konfigurację. - Jasność abstrakcji: Z zewnątrz, Pod jest adresowalną jednostką sieciową. Aplikacja nie musi wiedzieć, że działa w kontenerze.
- Kompatybilność: Tradycyjne aplikacje, które oczekują bezpośredniego dostępu do portów sieciowych, mogą działać bez zmian.
Problemy:
Pody są fachowo mówiąc „efemeryczne”, a ściślej to ich adresy IP. Jako, że pody mogą być usuwane, restartowane lub przenoszone między węzłami w dowolnym momencie ich adres IP zmienia się za każdym razem. To prowadzi nas do potrzeby wyższej warstwy pewnego rodzaju abstrakcji jednak co do zasady – nie wolno opierać w praktyce komunikacji na adresach IP między podami bo choć ta komunikacja, kiedy adresy są znane – działa, to jednak te adresy bardzo często się zmieniają.
2. Komunikacja między podami
Aby w praktyce rozwiązać problem komunikacji na zmiennych adresach IP, w Kubernetesie niezbędny jest „service”. Czym jest service? W poprzedniej części tworzyliśmy dwa obiekty – deployment i service… przy czym deployment odpowiadał za aplikację, a service? Za tę komunikację sieciową.
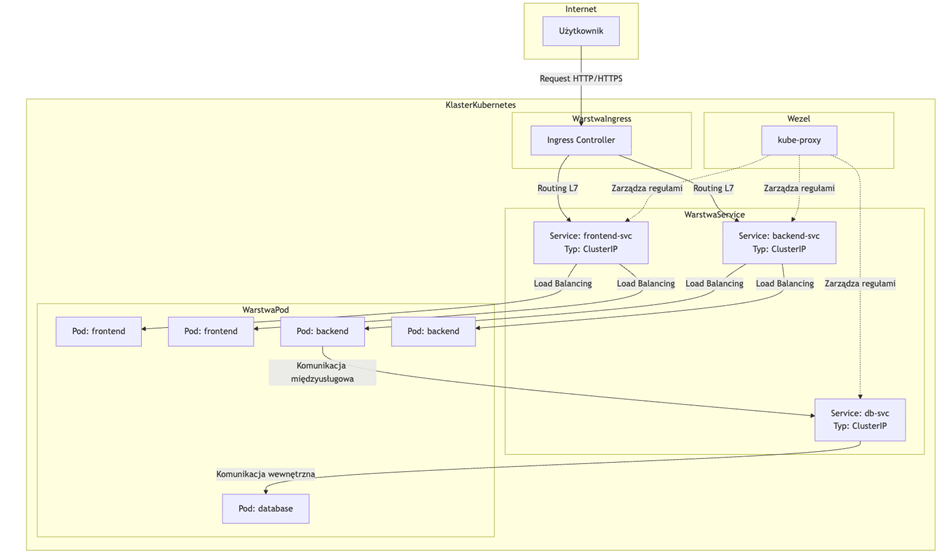
Service to warstwa abstrakcji nad Podami, która daje im stały adres IP i DNS. Dzięki temu aplikacje nie muszą znać IP poszczególnych Podów – łączą się przez nazwę usługi, a każdy Service ma własny ClusterIP (adres wirtualny), który rozkłada ruch do wszystkich Podów zgodnie z regułami load balancingu jeśli tych podów mamy więcej niż 1. Jak to działa w praktyce? Kiedy tworzymy Service, Kubernetes automatycznie tworzy odpowiadający mu endpoint (obiekt o tej samej nazwie) i stale go aktualizuje, śledząc adresy IP wszystkich Podów pasujących do selektora. Komponent kube-proxy, działający na każdym węźle, jest odpowiedzialny za implementację reguł sieciowych, które kierują ruch do właściwych Podów. Może to robić na kilka sposobów (iptables, ipvs), ale najpopularniejszym jest tryb iptables, gdzie kube-proxy tworzy dynamiczne reguły NAT, które przekierowują ruch wysłany na wirtualny adres IP Service’u na losowy adres IP jednego z backendowych Podów.
Typy Service’ów i ich zastosowania:
- ClusterIP (domyślny): Przydziela wewnętrzny, wirtualny IP z puli klastra. Service jest dostępny tylko wewnątrz klastra. Jest to idealne rozwiązanie dla komunikacji między mikroserwisami (np. gdy API backendowe musi komunikować się z bazą danych).
- NodePort: Tworzy Service typu ClusterIP i dodatkowo mapuje ten Service na ten sam port (z zakresu 30000-32767) na każdym węźle klastra. Dostęp do aplikacji uzyskuje się poprzez <ADRES_DOWOLNEGO_WĘZLA>:<SPECYFICZNY_PORT>. Użyteczny do debugowania lub dla usług, które muszą być tymczasowo wystawione na zewnątrz bez LoadBalancera.
- LoadBalancer: Tworzy Service typu NodePort i dodatkowo próbuje aprowizować zewnętrznego load balancera w supportowanych środowiskach chmurowych (AWS, GCP, Azure). Dostawca chmury automatycznie przydziela zewnętrzny adres IP i konfiguruje load balancera, który kieruje ruch do węzłów klastra na porcie NodePort. Na serwerach dedykowanych czy VPS wymaga dodatkowych rozwiązań, takich jak MetalLB, które „symulują” takiego dostawcę chmury.
Możliwe drogi komunikacji sieciowej:
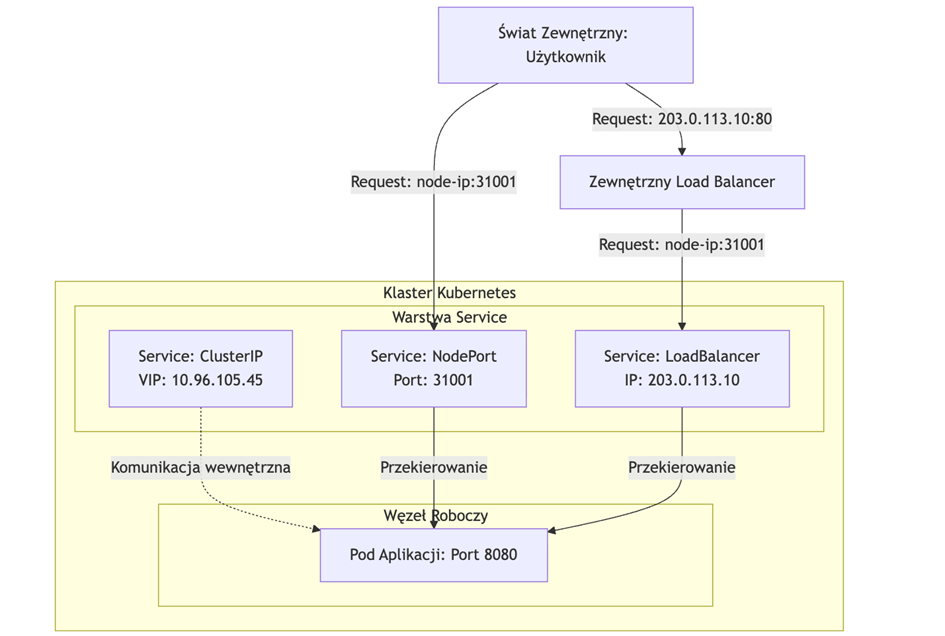
Na tym etapie należy odwołać się do części 2 „Praktycznego Kubernetesa”. Pod koniec tej części aplikacja była już wystawiona, lecz aby zobrazować jej działanie konieczne stało się udostępnienie zasobu na zewnątrz. Wspomniano, że istnieje co najmniej kilka rozwiązań tego problemu; zastosowano jednak prosty hack polegający na utworzeniu wewnętrznego tunelu w celu zasymulowania dla serwera ruchu „lokalnego”. Wynika to z faktu, że kube-proxy zwykle opiera się na zestawie dynamicznych reguł NAT, które przepuszczają jedynie ruch postrzegany jako lokalny, przez co niemożliwe jest wystawienie na porcie 80 prostego nginx-a albo tunelu typu socat czy xinted – ruch przychodzi i wychodzi z adresów, które nie są dopuszczone w iptables przez kube-proxy.
3. Ingress
W świecie mikroserwisów i aplikacji chmurowych, samo udostępnienie usługi na zewnątrz klastra to za mało. Prawdziwe wyzwanie polega na inteligentnym, bezpiecznym i efektywnym zarządzaniu ruchem przychodzącym do dziesiątek lub setek wewnętrznych usług. Podczas gdy Service typu LoadBalancer zapewnia podstawową funkcjonalność wystawienia pojedynczej usługi, jest to rozwiązanie prymitywne, kosztowne i niebezpieczne w skali. Ingress nie jest jedynie „kolejnym typem Service’u”; to jest fundamentalna abstrakcja, która przenosi model operacyjny Kubernetesa z warstwy transportowej (L4) do warstwy aplikacji (L7), stając się niezbędnym mózgiem operacyjnym dla nowoczesnych, wielousługowych architektur.
Jak to działa na przykładzie diagramu:
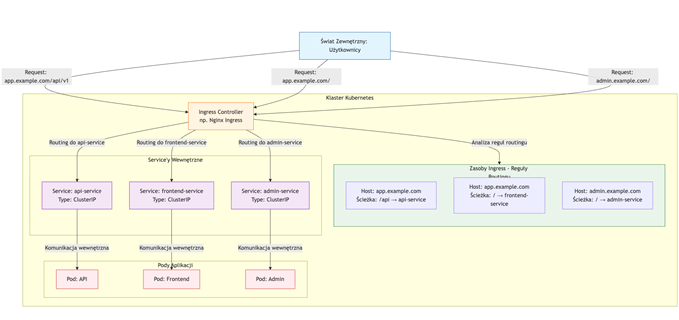
Ingress to w skrócie warstwa kontrolująca ruch przychodzący do klastra. Formalnie: jest to obiekt w Kubernetes definiujący reguły routingu HTTP(S), TLS oraz host-based/path-based routing, a za jego egzekucję odpowiada specjalny komponent – Ingress Controller (np. NGINX, Traefik, HAProxy, Kong).
Można myśleć o nim jak o bramie wejściowej do całego klastra:
- przejmuje ruch z Internetu,
- sprawdza reguły,
- kieruje żądania do odpowiednich serwisów,
- dodatkowo pełni rolę reverse proxy i load balancera warstwy 7.
Ale dlaczego ten ingress jest niezbędny? Można wyobrazić sobie architekturę złożoną z 50 mikroserwisów, z których każdy wymaga publicznej dostępności. Użycie Service’u typu LoadBalancer dla każdego z nich prowadzi do horrendalnego podniesienia kosztów, podniesienia złożoności architektury, podniesienia ryzyka awarii i wielu wielu więcej problemów:
- Koszt: Każdy Service
LoadBalancerw chmurze publicznej (AWS ELB, GCP CLB, Azure ALB) to osobny, płatny zasób. Pięćdziesiąt load balancerów to ogromny, niepotrzebny koszt operacyjny. - Marnowanie Zasobów: Każdy load balancer zużywa publiczne adresy IP, których pula jest ograniczona. Pięćdziesiąt usług to pięćdziesiąt adresów IP, co jest rażąco nieefektywne kosztowo.
- Złożoność Zarządzania: Zarządzanie pięćdziesięcioma zewnętrznymi endpointami, ich konfiguracją bezpieczeństwa (security groups) i monitorowaniem to prosty przepis na to, że o czymś zapomnimy.
- Bezpieczeństwo: Wystawienie pięćdziesięciu punktów końcowych na świat pięćdziesięciokrotnie zwiększa powierzchnię ataku aplikacji.
Ingress rozwiązuje ten problem bowiem jeden Ingress Controller, wystawiony przez jeden Service LoadBalancer, może obsłużyć routing dla wszystkich pięćdziesięciu mikroserwisów. To oszczędność kosztów, zasobów i nakładu pracy o rząd wielkości. Podczas gdy Service działa na warstwie 4 (TCP/UDP), Ingress operuje na warstwie 7 (HTTP/HTTPS). Ta różnica poziomów abstrakcji otwiera drzwi do zaawansowanych funkcji jak ruting na bazie nagłówków, na bazie path, cannary releases czy sticky sessions, ale nie tylko. Centralny ingress to także centralne zarządzanie choćby certyfikatami SSL. Wyobraźmy sobie podgrywanie certyfikatów na 50 różnych endpointach.




Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.