Prawdziwe zrozumienie Kubernetesa przychodzi przez pewnego rodzaju doświadczenie, czyli poprzez uruchamianie poleceń, obserwowanie działania klastra i naprawianie nieuniknionych błędów. Bez tego teoria będzie tylko teorią, dlatego przejdziemy krok po kroku przez proces instalacji i konfiguracji pierwszego, w pełni funkcjonalnego klastra Kubernetes. Praca zostanie wykonana na systemie Debian, w tym wypadku wersji 12.
Wykorzystamy Minikube – narzędzie, które pozwala na uruchomienie jednowęzłowego klastra Kubernetes na pojedynczej maszynie. Jest to idealne rozwiązanie do nauki, developmentu i testowania, ponieważ jest lekkie, stosunkowo łatwe w konfiguracji i wiernie oddaje działanie pełnoprawnego klastra. Polem działania będzie czysty serwer z systemem Debian 12. Zostaną zainstalowane niezbędne komponenty, uruchomiony klaster, a na koniec, przy użyciu narzędzia kubectl, wdrożona i udostępniona pierwsza aplikacja.
- Instalacja i konfiguracja Minikube w systemie Debian 12
W tym punkcie zostanie przeprowadzona instalacja oraz konfiguracja Minikube.
1.1 Na początek niezbędne pakiety:
apt install -y curl wget apt-transport-https
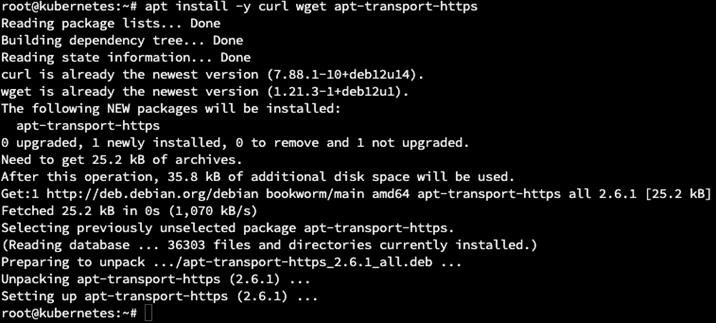
1.2. Należy dodać oficjalne repozytorium dla Dockera.
install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg –dearmor -o /etc/apt/keyrings/docker.gpg
chmod a+r /etc/apt/keyrings/docker.gpg
echo „deb [arch=”$(dpkg –print-architecture)” signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
„$(. /etc/os-release && echo „$VERSION_CODENAME”)” stable” | tee /etc/apt/sources.list.d/docker.list > /dev/null
Instalacja Docker’a, jest on oczywiście niezbędny do prawidłowego działania Kubernetesa.
apt update
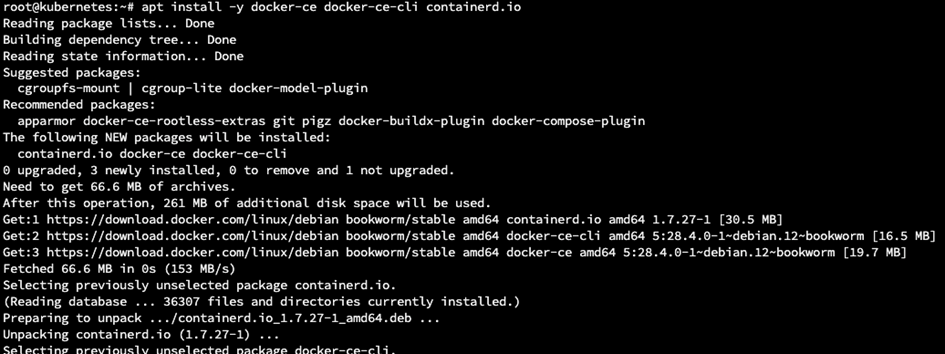
apt install -y docker-ce docker-ce-cli containerd.io
TIP: pamiętaj by dodać swojego użytkownika, z którego uruchomisz aplikację do grupy dockera.
1.3. Instalacja kubectl
usermod -aG docker $USER
Narzędzie kubectl jest to klient do sterowania klastrem Kubernetesa i jest niezbędny do interakcji w minikube.
curl -LO https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl
install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
Sprawdzenie czy jest poprawnie zainstalowane.
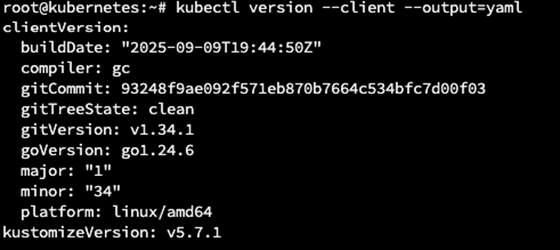
kubectl version –client –output=yaml
Instalacja Minikube.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
install minikube-linux-amd64 /usr/local/bin/minikube
Weryfikacja instalacji.
minikube version

1.4. Uruchomienie klastra Minikube
minikube start –driver=docker
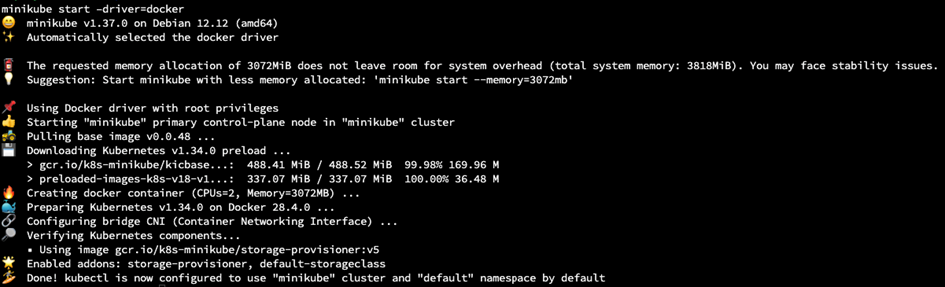
W ten sposób inicjowany jest nowy klaster Kubernetes. Flaga –driver=docker mówi Minikube, aby używał Dockera jako środowiska uruchomieniowego dla kontenerów Kubernetes.
Wśród dostępnych driverów dla systemu Linux można znaleźć: kvm2, virtualbox, quemu, none, podman czy ssh. Zostanie użyty Docker, bo jest on najbardziej popularny.
Weryfikujemy, czy klaster działa.
minikube status
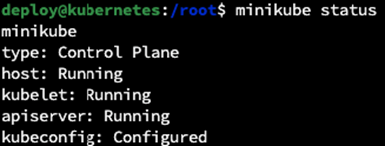
kubectl get nodes

1.5. Administracja i zarządzanie klastrem, najważniejsze polecenia
Na początek należy poznać podstawowe polecenia do zarządzania klastrem:
kubectl get <resource>
Wyświetla listę zasobów (np. pods, services, nodes).
kubectl describe <resource> <name>
Pokażę szczegółowy opis danego zasobu.
kubectl create|apply -f <file.yaml>
Tworzy zasób(oby) z pliku manifestu YAML. apply jest preferowane, bo jest idempotentne.
kubectl delete <resource> <name>
Usuwa zasób.
kubectl logs <pod-name>
Wyświetla logi z kontenera w Podzie.
kubectl exec -it <pod-name> — /bin/bash
Uruchamia interaktywny terminal (bash) w środku konkretnego poda.
- Tworzymy pierwszy pod i serwis
Nie będzie tu tworzona zaawansowana aplikacja, takie jak API czy złożona architektura. Zostanie wdrożony prosty przykład, znany z ekosystemu Dockera jako klasyczne „Hello World”, w postaci statycznej strony internetowej.
Działanie to należy podzielić na dwie odrębne sekcje: Deployment oraz Service. Choć technicznie możliwe jest umieszczenie obu zasobów w jednym pliku YAML, dobrą praktyką – zgodną z fundamentalną zasadą projektowania w Kubernetes – jest ich rozdzielenie wynika to z pojedynczej odpowiedzialności (Single Responsibility Principle).
Dlatego uruchamiając w tej chwili aplikację zostaną przygotowane dwa pliki yaml – odpowiedzialne za deployment i za serwis.
Dlaczego tak? Zadaniem deploymentu jest zarządzanie cyklem życia podów i odpowiedzialność za to, że uruchomiona pozostaje dokładnie zadana liczba podów, nie więcej, nie mniej. Deployment odpowiada też za wdrożenie nowej wersji, wycofanie poprzedniej, wadliwej, restarty podów.
2.1. Struktura yamla
Zadaniem serwisu jest zapewnienie stałego dostępu sieciowego do podów. Zapewnia on stabilne połączenie sieciowe, przydziela adresy IP, DNS czy porty, dzięki czemu możliwa jest komunikacja między podami. Działa to trochę jak wewnętrzny loadbalanser, który wykrywa pody i kieruje do nich ruch.
Pomimo tego, że dla deploymentu i serwisu tworzone są oddzielne pliki yaml, to mają one cechy wspólne i są względnie podobne.
apiVersion: … # Pole obowiązkowe: Która wersja API Kubernetesa definiuje ten obiekt?
kind: … # Pole obowiązkowe: Jakiego rodzaju obiekt tworzymy? (Deployment, Service, Pod, itp.)
metadata: # Pole obowiązkowe: Dane identyfikujące obiekt.
name: … # Pole obowiązkowe: Unikalna nazwa tego obiektu w namespace.
labels: # Opcjonalne: Etykiety przypisane do tego obiektu.
klucz: wartosc
spec: # Pole obowiązkowe: „Specyfikacja” – to jest sedno, tutaj definiujemy pożądany stan obiektu.
… # Tutaj znajdują się specyficzne właściwości dla danego `kind`.
2.2. Deployment
Teraz tworzymy przykładowy plik deploymentu
vi nginx-deployment.yaml
apiVersion: apps/v1 # Deployment jest częścią API `apps` w wersji `v1`.
kind: Deployment # Definiujemy obiekt typu Deployment.
metadata:
name: nginx-hello-world # Nazwa naszego Deploymentu.
# Sekcja `spec` Deploymentu opisuje POŻĄDANY STAN dla Podów, którymi ma zarządzać.
spec:
replicas: 2 # Żądana liczba identycznych replik Podów (pożądany stan: „2 działające kopie”).
selector: # CRITICAL: Jak Deployment znajduje swoje Pody do zarządzania?
matchLabels:
app: nginx-app # „Zarządzaj wszystkimi Podami, które mają label `app: nginx-app`.”
template: # To jest szablon, z którego Deployment będzie tworzył nowe Pody.
metadata: # Metadata dla POSZCZEGÓLNYCH Podów tworzonych z tego szablonu.
labels: # Etykiety, które zostaną nadane każdemu nowo stworzonemu Podowi.
app: nginx-app # MUST match `spec.selector.matchLabels` above!
spec: # Specyfikacja dla POSZCZEGÓLNYCH Podów (to jest spec Pod, a nie Deployment).
containers: # Lista kontenerów, które będą uruchomione w Podzie.
– name: nginx-container # Nazwa kontenera wewnątrz Pod-a.
image: nginx:latest # Który obraz kontenera pobrać i uruchomić.
ports: # Informacja, że kontener nasłuchuje na danym porcie (bardziej informacyjnie niż funkcjonalnie).
– containerPort: 80
2.3. Serwis
Tworzymy serwis na kanwie pliku wspólnego
vi nginx-service.yml
apiVersion: v1
kind: Service # Definiujemy obiekt typu Service.
metadata:
name: nginx-service # Nazwa naszej usługi.
spec:
type: NodePort
selector:
app: nginx-app
ports:
– port: 80
targetPort: 80
2.4. Uruchomienie
nodePort: 30080 – kierujemy ruch z portu 80 lokalnie na podzie na port node’a 30080 – wystawiamy go
Aplikujemy zmiany i stawiamy środowisko:
kubectl apply -f nginx-deployment.yml
kubectl apply -f nginx-service.yml

Aby uzyskać dostęp do aplikacji poprzez nasz wewnętrzny LoadBalanser użyjemy polecenia:
minikube service nginx-service –url
który zwróci nam serwis:

2.5. Podgląd
Zanim przejdziemy do strony internetowej, zajrzyjmy do tego co aktualnie nasza infrastruktura posiada, co stworzyliśmy i czym możemy już zarządzać.
kubectl get pods

Zgodnie z żądaniem, mamy dwa pody.
kubectl get deployments

kubectl get services

kubectl describe service nginx-service
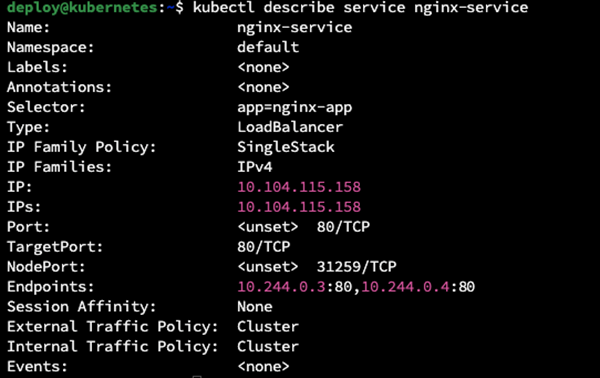
- Sprawdzenie czy działa
Lokalnie po porcie powinno działać bez problemu, ale jeśli robimy to testowo na serwerze VPS to należałoby podłączyć się tunelem do serwera lub ustawić jakieś proxy typu socks, aby ten ruch obsłużyć.
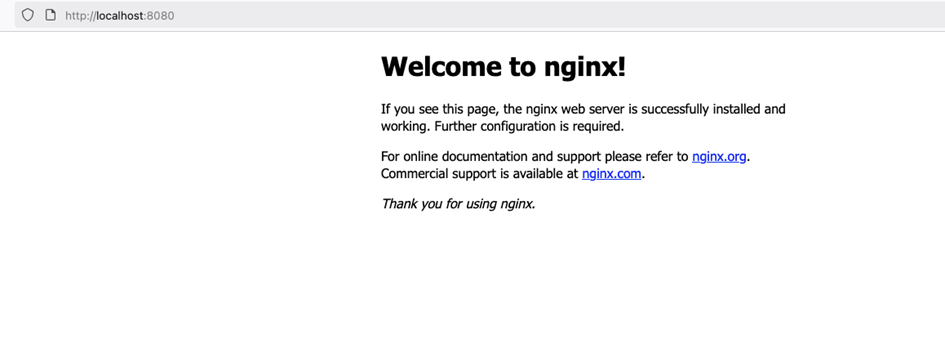
- Podsumowanie
Udało się uruchomić działające środowisko Kubernetes na Minikube i połączyć się z aplikacją poprzez lokalne adresy klastra, a dostęp z zewnątrz uzyskaliśmy dzięki tunelowaniu (SOCKS/SSH port-forward). W tym podejściu nie musieliśmy ingerować w złożone reguły iptables ani modyfikować sieci Dockera – wystarczyło proste przekierowanie ruchu. To dobre rozwiązanie na etapie nauki i testów, bo pozwala w bezpieczny sposób pracować z usługami i zasobami Kubernetesa w izolowanym środowisku.




Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.