
Czym jest Kubernetes, po co powstał i dlaczego stał się niezbędny?
Jeszcze kilka lat temu firmy, które wdrażały aplikacje w środowiskach produkcyjnych, musiały ręcznie zarządzać serwerami, instalacjami i konfiguracjami. Pojawienie się konteneryzacji (np. Docker) było przełomem – aplikacje stały się lżejsze, przenośne i łatwiejsze do wdrażania. Jednak wraz ze wzrostem skali pojawiły się nowe problemy jak na przykład:
- jak efektywnie zarządzać setkami czy tysiącami kontenerów jednocześnie?
- Jak zapewnić, by były odporne na awarie?
- Jak skalować je pod obciążeniem?
- Jak zarządzać ich komunikacją aktualizacjami i dostępem do tajemnych danych, takich jak hasła czy klucze API?
- Jak bezpiecznie wdrażać nowe wersje i cofać je, gdy coś pójdzie nie tak?
- Jak efektywnie wykorzystywać zasoby serwerów, umieszczając kontenery tam, gdzie jest wolne CPU/RAM?
- Jak automatycznie restartować padnięte kontenery, zastępować uszkodzone węzły i zabijać kontenery, które nie odpowiadają?
Tu na scenę wkracza właśnie Kubernetes – system, który zrewolucjonizował świat IT, stając się standardem w orkiestracji kontenerów. Obecnie jest używany przez największe organizacje na świecie i jest fundamentem nowoczesnych architektur chmurowych. Choć powstało wiele narzędzi (tzw. „orchestratorów”), jak Docker Swarm, Apache Mesos, czy Nomad to każde z nich oferowało swoje własne, unikalne podejście. To prowadziło do fragmentacji i braku przenośności. Świat potrzebował jednego, wspólnego standardu – „Linuxa dla chmur” – warstwy abstrakcji, która pozwalałaby w jednolity sposób zarządzać zasobami klastrowymi, niezależnie od tego, czy działa to lokalnie, u dostawcy chmurowego A, B czy C. Tym standardem stał się Kubernetes (często skracany do k8s). Nie jest to tylko narzędzie; to jest platforma, ekosystem i de facto standard branżowy do automatyzacji wdrażania, skalowania i zarządzania aplikacjami kontenerowymi. Zrozumienie Kubernetesa to dziś nie opcja, a konieczność dla każdego administratora, architekta czy dewelopera pracującego z nowoczesnymi aplikacjami.
Historycznie korzenie Kubernetesa sięgają Google. Przez ponad dekadę Google używał wewnętrznego systemu o nazwie Borg (a później Omega) do zarządzania swoimi niewyobrażalnie wielkimi aplikacjami, takimi jak Wyszukiwarka czy Gmail. Borg zarządzał milionami kontenerów tygodniowo. W 2014 roku Google opublikował Kubernetes jako projekt open-source, oparty na latach doświadczeń zdobytych przy Borgu. W 2015 roku Kubernetes został przyjęty pod skrzydła Cloud Native Computing Foundation (CNCF), co zapewniło mu neutralność i napędziło niesamowity rozwój społeczności. Dziś to jeden z największych projektów open-source na świecie.
Kubernets – Podstawowe pojęcia
Aby zrozumieć Kubernetesa, trzeba opanować jego podstawowe narzędzia, słownictwo. Bez zrozumienia podstaw nie da się wejść głębiej i pracować z narzędziami.
Klaster (Cluster): To jest całość. Podstawowa jednostka w Kubernetesie. Klaster to zestaw maszyn (fizycznych lub wirtualnych), zwanych węzłami (Nodes), które połączone są ze sobą w sieć i pracują razem jako jedna, potężna całość. To w klastrze uruchamiane są Twoje aplikacje. Klaster daje wrażenie pojedynczego, potężnego komputera złożonego z wielu (nawet tysięcy) małych komputerów.
Węzeł (Node): Pojedyncza maszyna (serwer/komputer) w klastrze. Może to być serwer w Twojej serwerowni, maszyna wirtualna w chmurze (np. AWS EC2, Azure VM) czy nawet Twój laptop z Minikube. Węzły dzielimy na:
Master Node (Control Plane): Mózg całego klastra. To on podejmuje globalne decyzje (np. gdzie uruchomić kontener), wykrywa i reaguje na zdarzenia (np. awarię węzła). Zazwyczaj dla odporności działa w konfiguracji wielowęzłowej.
- API Server – centralny punkt komunikacji (REST API).
- Scheduler – decyduje, na którym node uruchomić pod.
- Controller Manager – monitoruje stan klastra i pilnuje, aby odpowiadał oczekiwanemu stanowi.
- etcd – rozproszona baza danych przechowująca konfigurację i stan klastra.
Worker Node: To na nich faktycznie uruchamiane są Twoje aplikacje. Każdy Worker Node musi mieć zainstalowane:
- Kubelet: Agent, który komunikuje się z Control Plane i zapewnia, że kontenery w Podzie są uruchomione i działające. To most między Node a Control Plane.
- Container Runtime: Oprogramowanie odpowiedzialne za uruchamianie kontenerów (np. Docker, containerd, CRI-O).
- Kube-proxy: Komponent sieciowy, który zarządza regułami sieciowymi i routingiem na węźle.
Pod: Najmniejsza i najprostsza jednostka wdrożeniowa w obiekcie Kubernetesa. To abstrakcja reprezentująca pojedyncze wystąpienie aplikacji. Pod to „opakowanie na jeden lub więcej kontenerów”, które współdzielą:
- Przestrzeń nazw sieci (mają ten sam adres IP)
- Zasoby (CPU, RAM)
- Woluminy (dyskowe)
W praktyce, większość Podów zawiera jeden kontener. Pod z wieloma kontenerami używany jest w specyficznych przypadkach, gdy kontenery są ściśle powiązane (np. kontener główny i kontener-helpers do logowania czy synchronizacji plików).
Architektura – czyli jak to wszystko jest ze sobą połączone?
Najlepiej wyjaśnić to na prostym diagramie, który pokazuje jak to mniej więcej jest połączone ze sobą, co za co odpowiada i od czego zależy.
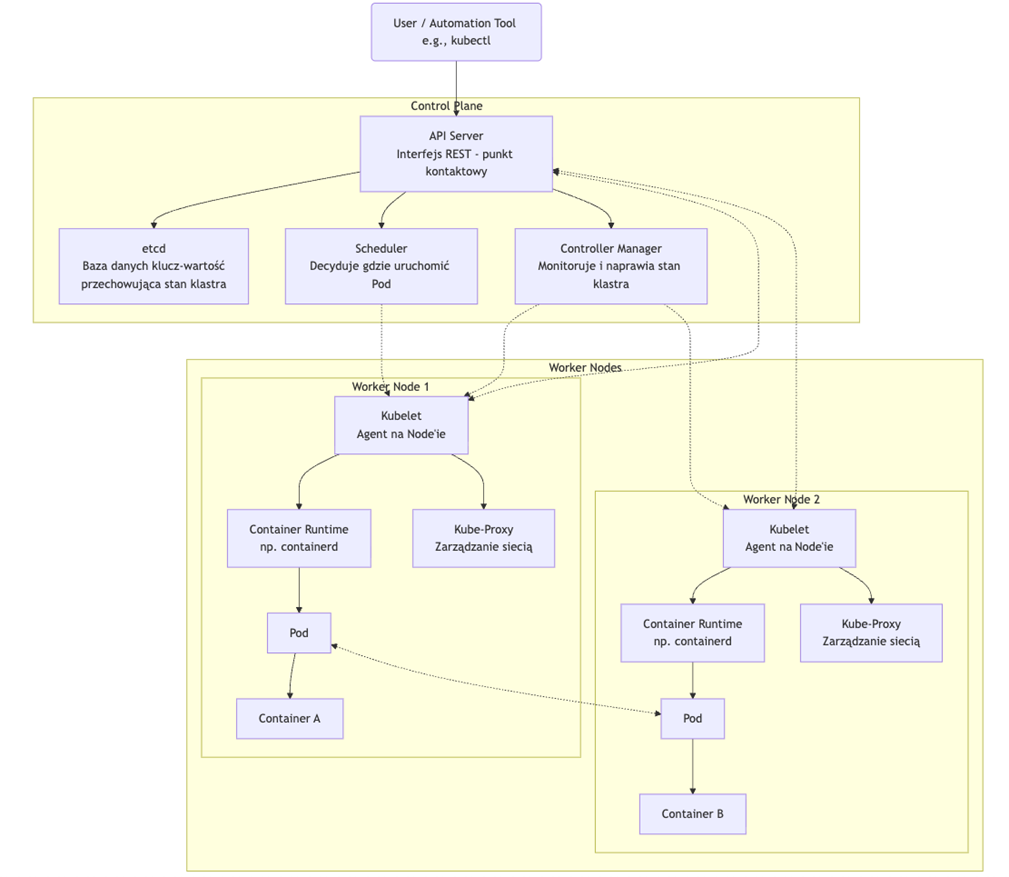
Kiedy cofniemy się do poprzedniego punktu, zauważymy rozpisane poszczególne elementy w tym układzie. Poniżej znajdziesz opisany w skrócie flow
Opis przepływu i powiązań:
- Interakcja użytkownika: Administrator lub narzędzia automatyzacji (np. Terraform) komunikują się z API Server za pomocą narzędzia
kubectllub bezpośrednio przez REST API, aby zadeklarować pożądany stan klastra (np. „uruchom 5 replik mojej aplikacji”). - Przechowywanie stanu: API Server waliduje i zapisuje ten żądany stan w etcd, który działa jako źródło stanu.
- Synchronizacja stanu: Wszystkie komponenty Control Plane (Scheduler, Controller Manager) nie komunikują się bezpośrednio z
etcd, lecz nasłuchują na zmiany stanu poprzez API Server. - Planowanie: Gdy API Server powiadamia o nowym Podzie do uruchomienia, Scheduler analizuje bieżący stan klastra (dostępność zasobów na węzłach) i podejmuje decyzję, na którym Worker Node powinien zostać uruchomiony. Decyzję tę publikuje z powrotem przez API Server.
- Wykonanie na węźle: Kubelet na docelowym Worker Node stale nasłuchuje poleceń z API Server. Wychwytuje informację, że na jego węźle ma być uruchomiony Pod.
- Uruchomienie kontenera: Kubelet instruuje Container Runtime (np. containerd), aby pobrał image kontenera i uruchomił Pod.
- Konfiguracja sieci: Kubelet konfiguruje również Kube-Proxy na swoim węźle, aby zapewniał reguły routingu i load balancing dla usług uruchomionych na Podach.
- Utrzymywanie stanu: Controller Manager ciągle monitoruje stan klastra (czy liczba uruchomionych Podów zgadza się z zadeklarowaną). W przypadku wykrycia rozbieżności (np. Pod uległ awarii) podejmuje działania naprawcze, wydając polecenia przez API Server, które finalnie trafiają do odpowiedniego Kubelet.
- Komunikacja między Podami: Sieć pomiędzy Podami, niezależnie od tego, na którym węźle się znajdują, jest zapewniana przez plugin CNI (Container Network Interface), który nie jest bezpośrednio pokazany na diagramie, ale jest kluczowym komponentem umożliwiającym komunikację
Pod <-> Pod.
Podsumowanie
Kubernetes to otwartoźródłowy system orkiestracji kontenerów, który stał się branżowym standardem dzięki swojej skalowalności, automatyzacji i niezawodności w zarządzaniu aplikacjami. Powstał w Google jako odpowiedź na potrzebę kontrolowania rosnącej liczby kontenerów i dziś jest fundamentem architektur mikroserwisowych oraz chmurowych, używanym przez największe organizacje na świecie. Jego architektura opiera się na płaszczyźnie sterowania (API Server, Scheduler, Controller Manager, etcd) oraz węzłach roboczych (Kubelet, Kube-proxy, Container Runtime), które wspólnie umożliwiają sprawne uruchamianie i zarządzanie Podami. Dzięki temu stał się niezastąpionym narzędziem w arsenale każdego administratora, wykorzystywanym przez czołowe organizacje na świecie do budowy elastycznych, odpornych i przenośnych systemów opartych na mikrousługach i chmurze.
W kolejnej części zajmiemy się praktyczną konfiguracją środowiska Kubernetes na systemie Linux Debian, przygotowując fundament pod dalsze eksperymenty i wdrażanie rzeczywistych aplikacji.




Zostaw komentarz
Musisz się zalogować lub zarejestrować aby dodać nowy komentarz.